
References: Jacobson88, sec 2, appendix A
If a packet is lost, then we run out of window, have to wait for a timeout to occur, retransmit the lost packet and wait for a cumulative acknowledgement reopening the window. The lower the timeout is, the less time we have the transmission stopped. On the other hand, if the TimeOuts are too small, then we risk to retransmit packets that have actually not been dropped (they are just taking too long to arrive), making inefficient use of the bandwidth and increasing the congestion in the network. Therefore, the better the timeouts are adjusted, the better the protocol will perform.
How are the TimeOuts adjusted? The original RFC793 TCP sets the timeout to be twice the estimated RTT, which is estimated with the following average (a low-pass filter which cuts fast variations):
SRTT[i] = (1-a) * SRTT[i-1] + a * RTT
0 < a < 1; usually a = 1/8
RTO = 2 * SRTT
where RTT: Round Trip Time; SRTT: Smoothed RTT, RTO: Retransmit TimeOut
The first problem we can see with this estimation is the following: suppose a non-congested network such that the RTT remains nearly constant during a long time. Suddenly a packet is lost. After RTT seconds, we haven't seen its ACK -- it is almost certain that it has been dropped; however, we wait RTT seconds to retransmit it!
There is a second problem which is not so easy to see; we know from queueing theory that if the network load increases, the mean RTT grows and (the worst) its variance grows even more [TO BE COMPLETED WITH SOME QUEUING THEORY]. Therefore, it is possible that under such circumstances setting the RTO to only twice the measured RTT is too small and can result in regions where our retransmission timeout is shorter than the real RTT. What happens then is that we are thinking that packets that are taking too much time to arrive because of network congestion (but that are going to arrive) are being unnecesarily retransmitted, increasing the congestion even more. Jacobson claims that this will happen with network loads over 30%.
These two problems are illustrated in Applet 3.1.
Applet 3.1 |
|
|---|---|
|
|
This animation file: gzipped. The script used: rttvar.tcl Parameters for this animation: ns rttvar.tcl false 0.5 Parameters for the second graph: ns rttvar.tcl false 0.1 Description:All the links are 1Mbit/s, 100ms delay but n1-n2, which is 0.5 Mbit/s. All the hosts implements the RFC 793 TCP RTO estimation. n0 begins transmitting to n2 at t=0.5s. At t=1.5s all the other nodes begin transmitting to n2, so a big queue grows very fast in n1 and so does the RTT measured by n0. At t=3.5 all the other sources stop transmitting so that the RTT decreases to the initial values. The following graphs shows the evolution of the measured RTT and how the RTO is adjusted. The first uses the standard 500ms-Tick Clock RFC 793 TCP uses to measure the RTT; the second uses a 100ms-Tick Clock; this makes the RTT graph much smoother. 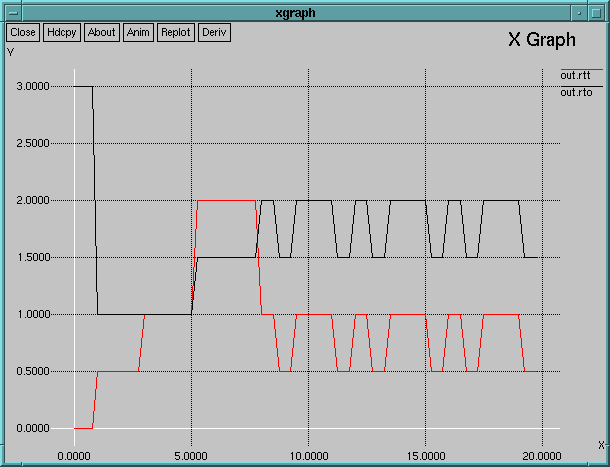 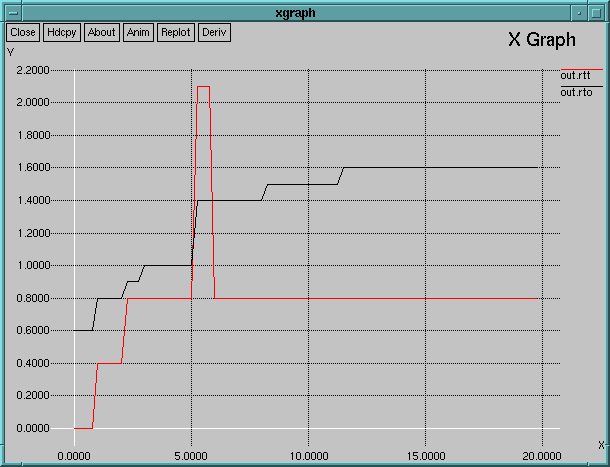
We can see two things: first, RFC 793 estimation is not fast enough to follow the sudden RTT change. RFC 793 RTO estimation is under the actual RTT of the system for a while; this could cause retransmission of packets that actually have not been lost. Second, when the system is stabilized close to the end of the experiment, timeout is adjusted to a too big value (twice the RTT). If we have a drop in this region, we have to wait more than twice the minimum necessary to retransmit. |
Jacobson proposed [Jacobson88] to calculate the RTO as:
RTO = SRTT + u * Dev(RTT)
Where Dev(RTT) is the mean deviation of the RTT samples and u uses to be u=4. He provided a fast algorithm for making the calculus which can be consulted in [Jacobson88], appendix A for the details.
If there is little difference between the sampled RTT and our estimation SRTT during long time (Dev(RTT) --> 0), then we can be confident and state that SRTT is a good estimation of RTT. Therefore, if an acknowledgement takes more than SRTT seconds to arrive, we can begin to think about retrasmitting it. On the other hand, if RTT shows a high variance (big Dev(RTT)), then it is better not to be so confident about our estimation, an have a security margin proportional to our uncertainy.
See Jacobson88, appendix A for the details.
See Jacobson88, appendix A.
With Jacobson variance estimation we can see that first, the timeout can adapt to sudden changes in the RTT. Second, when RTT remains constant for a long time, Jacobson gets a closer estimation of the RTT.
Applet 3.2 |
|
|---|---|
|
|
This animation file: gzipped. The script used: rttvar.tcl Parameters for this animation: ns rttvar.tcl true 0.5 Parameters for the second graph: ns rttvar.tcl true 0.1 Description:Same as Applet 3.1, but this time n0 implements Jacobson's RTT Variance estimation. The following is the graph obtained for a TCP-Tick of 100ms: 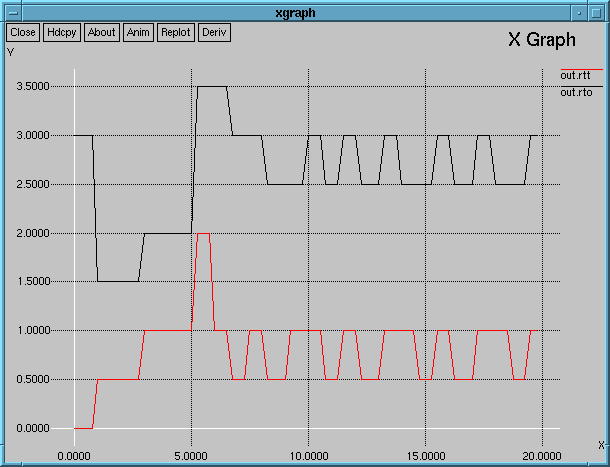
We can see that Jacobson estimation not only can adapt to the sudden growth of the RTT, but also follows the actual RTT much closer when the situation becomes normal at the end of the experiment. In Applet 3.1 we saw that a coarser TCP Tick results in a rougher graph, but the general shape was preserved; now, we take into account the variance of the RTT samples; if we are using a coarser 500ms clock, then the variance of the RTT samples increases because of the rounding, and that changes the shape of the graph: 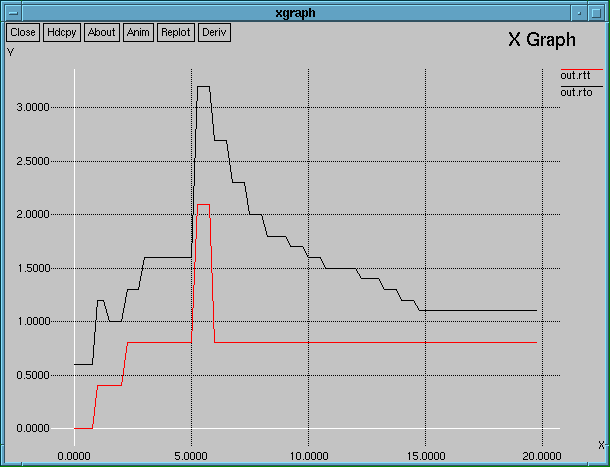
|