The lmbench benchmark also shows the 32p box performs slightly slower on the memory tests than then 16p box.
NOTE The tests on the IBM p690 are using early versions of the compilers and libraries, and we expect performance to continue to improve with new releases. Large page support and and page affinity will be provided soon and will also improve results. These tests were conducted in January, 2002.
The stream benchmark is a program that measures main memory throughput for several simple operations. The following shows the output from stream on the 16p and 32p p690.
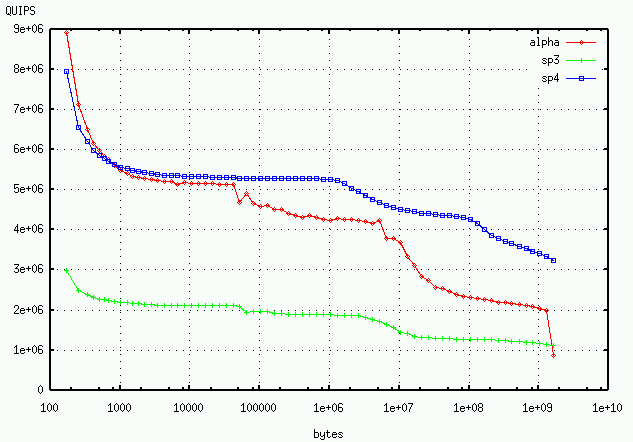
The hint
benchmark measures computation and memory efficiency as
the problem size increases.
The following graph also shows that a single processor test performs
more slowly on the 32p p690 than on the 16p.
The L1, L2 and L3 cache boundaries are visible.
The
lmbench benchmark
also shows the 32p box performs slightly slower on the memory tests
than then 16p box.
If we run concurrent stream benchmarks on multiple processors, then the 32p box gives higher aggregate throughput, the 4 MCM's providing more paths to memory. The following graphs the stream triad bandwidth.

It is expected that the power4 will show even higher memory
bandwidth when using 16 MB pages.
Most of the computational benchmarks show little difference for the 16p and 32p box because most execute out of the L2 and L3 cache.
The MPI intra-node performance for the 16p and 32p nodes was about the same, but the throughput for large messages is somewhat worse than what we measured a few months ago. The following graph shows bandwidth for communication between two processors on the same node using MPI from both EuroBen's mod1h and ParkBench comms1.

We re-ran some of the MPI parallel kernel benchmarks, but they user smaller messages sizes and did not exhibit any degradation from the earlier tests.