Sally Floyd, as part of her research on
high speed TCP,
has suggested
modifications to TCP slow start and to
TCP's AIMD for high delay, bandwidth networks.
As part of our Net100 research,
we have modified the Linux 2.4.16 Web100
kernel with Sally's slow-start
mods.
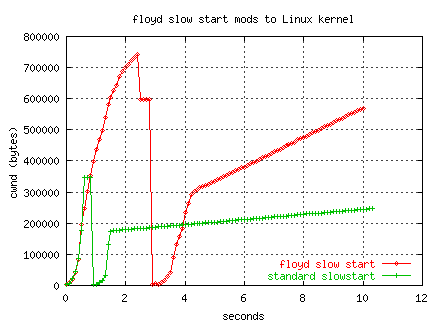
The following graph shows two TCP transfers from ORNL to NERSC (80ms RTT)
between two Linux boxes.
The NERSC box (receiver) is advertising a window of 2MB.
The ORNL sender uses a window of 1 MB.
One test was done with no tuning.
The other test used our Net100 tuning daemon
(WAD) to enable Sally's slow start
mods for the flow.
The test using standard slow-start experienced an early loss event in
slow start.
The flow using Sally's slow-start made it much further, but still
had a loss in the modified slow start (plus some other losses and timeout --
such is testing on the real internet....).
The WAD-tuned additive-increase is 6x .
The cwnd data was collected by a web100 tracer daemon (e.g., kernel
values of cwnd, not from tcpdump/tcptrace).
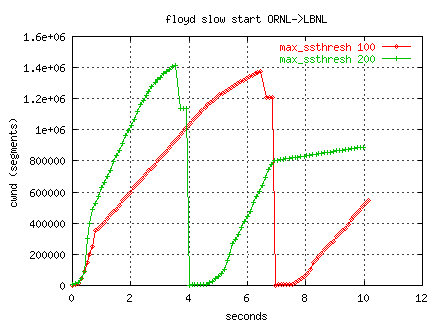
The following graph shows a WAD-tuned
TCP iperf transfer from ORNL to LBNL (80 mss RTT)
using Sally's slow-start with two different settings for max_ssthresh.
We also added Sally's slow start and her AIMD mods
to our TCP-over-UDP test harness
atou.
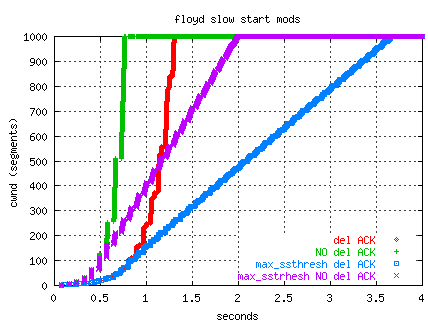
The following graph compares slow-start
for four TCP-over-UDP transfers from ORNL to NERSC
(OC12, RTT 80 ms)
with a max window size of 1000 segments.
The graph illustrates the stretching of slow-start with Floyd's max_ssthresh
set to 100 both with and without delayed ACKs.
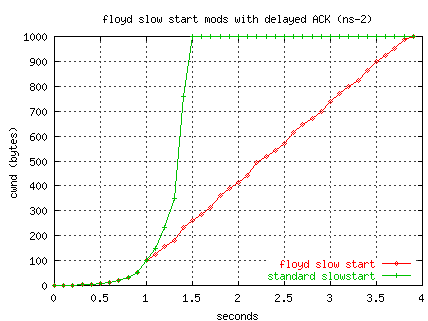
For comparison, the following plot shows an ns-2 simulation of Floyd's
slow-start and standard slow-start for a simulated network path
like the ORNL-NERSC path (300Mbs, 80 ms RTT, max window 1000, delayed ACKs).
In another test from PSC to LBL, we were getting losses in slow-start about 0.7 seconds into the transfer and the throughput was only 98 Mbs for the 10 second transfer (2000 segment window, 75 ms RTT, no delayed ACK). The congestion window at the time of the loss was 367 segments. Using Floyd's modified slow-start we eliminated losses and got 192 Mbs (max_ssthresh=100) and 204 Mbs (max_ssthresh=200).
The following image shows the stretched slow-start for a TCP-over-UDP transfer
from ORNL to CERN (RTT 190 ms) with max window set to 1000 segments
and the server is not doing delayed ACKs.
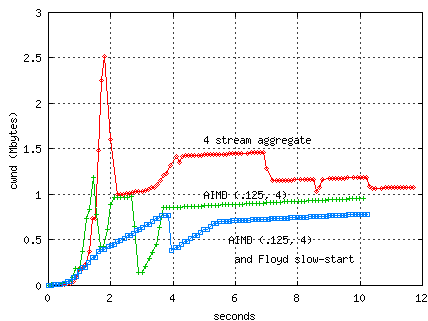
The following image compares three TCP transfers from ORNL to CERN.
One using 4 parallel streams, the other two are WAD-tuned with AIMD (0.125,4)
to try and approximate the parallel stream peformance.
One stream uses Floyd's modified slow start, and in this particular
test, attains only 29 Mbs compared with 38 Mbs for the other stream.
The aggregate parallel stream achieved 82 Mbs.
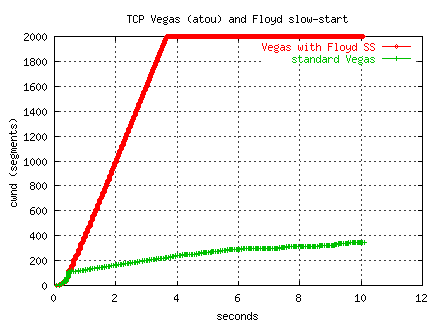
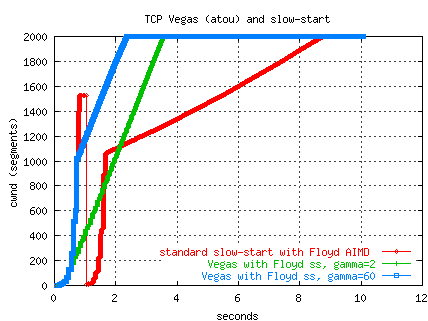
We have experimented using the Vegas gamma threshold during slow-start
to initiate Floyd's slow start (rather than max_ssthresh).
The figure below shows two transfers using a Vegas implementation
over our TCP-over-UDP from PSC to ORNL (OC12, 77ms RTT).
The standard Vegas exits slow-start if the Vegas delta is larger
than gamma and enters congestion avoidance phase.
The standard Vegas (actually using the Floyd AIMD mods) slowly increases
the window in congestion avoidance phase, further dampened by the Vegas
alpha/beta (1/3 in this test) and only reaches 36 Mbs.
The second transfer switches to Floyd's slow-start when gamma is exceeded.
Both transfers exceed gamma at about the 0.5 seconds into the transfer.
The Floyd version climbs quickly to the limiting window of 2000 segments
and reaches an average throughput of 232 Mbs -- nearly a factor of 8
improvement.
Interestingly, for these tests,
the cwnd value when gamma (1) is exceeded is around 120 segments,
close to Floyd's suggested max_ssthresh of 100.
The figure below illustrates three different TCP-over-UDP
transfers from PSC to ORNL.
The path was exhibiting packet drops during slow-start.
The standard slow-start algorithm suffers a loss and recovers using
Floyd's AIMD and reaches an average throughput of 198 Mbs after 10 seconds.
By comparison, the Vegas-controlled transfers exit standard slow-start
when gamma is exceeded and switch to Floyd's modified slow-start
and have no packet losses.
The Vegas flow with a gamma of 2 reaches 219 Mbs,
the flow with a gamma of 60 reaches 229 Mbs.
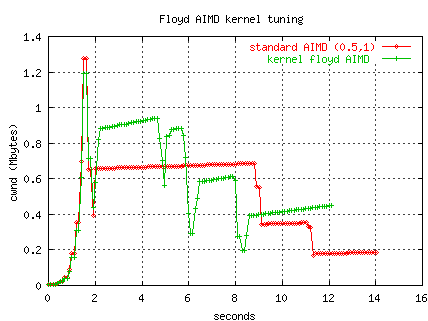
Floyd's modified AIMD
We have installed Sally's AIMD mods in the Linux kernel,
and our WAD
has an option to periodically (every 0.1 seconds)
tune AIMD values for designated flows using Sally's table.
The following plot compares two transfers from ORNL to CERN (160 ms RTT).
One transfer uses standard TCP AIMD (0.5,1), and the second
uses the kernel version of Floyd's modified AIMD.
The effect
of the altered decrement and increment is apparent.
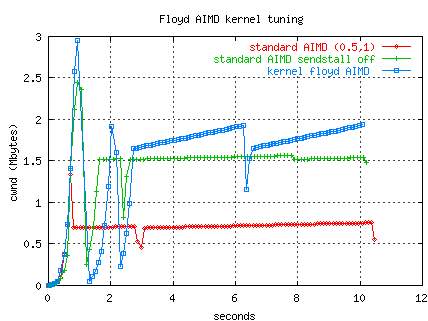
As another example,
the following plot compares three data transfers from ORNL to NERSC (OC12,
80 ms RTT).
Two transfers use standard TCP AIMD (0.5,1), slow-start is prematurely
terminated in one flow by a Linux "sendstall" -- NIC send buffer overrun.
In the second flow, we have used the WAD to disable sendstall's.
The third flow uses Floyd's modified AIMD.
(As always with tests on the "live" Internet, results vary.)
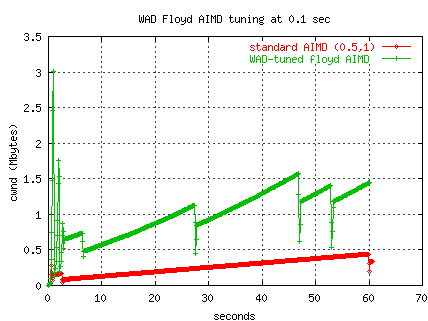
Tierney of LBNL has done more systematic testing in October of 2002 of Floyd's HSTCP. Here are some early results for testing HSTCP in the net100 kernel (2.4.19). These results are averages of 6-30 30 second iperf tests for each path.
In the following plot, we have used the WAD at 0.1 second intervals
to tune the flows.
(The kernel implementation continuously updates the AIMD values.)
One can see the slope of the recovery increasing
as cwnd increases, and one can see that the multiplicative decrease
is no longer 0.5 for the WAD/Floyd tuned flow.
Two tests are illustrated using 2 MB buffers for a 60 second
transfer from ORNL to LBNL (OC12, 80 ms RTT).
(The better slow-start of the Floyd flow is just the luck of that
particular test.)
The following graphs shows a TCP-over-UDP
transfer from ORNL to NERSC
(OC12, RTT 87 ms)
with a max window size of 1000 segments.
This path often experiences loss during slow start.
The reciever is not doing
delayed ACKs. Floyd's max_ssthresh is set to 100 segments
and that stretches the
slow start by about 1.8 seconds.
There is a single loss at 4.73 seconds.
Floyd's modified AIMD for a cwnd of 1000 segments is to reduce cwnd
by 0.329878 (rather than 0.5 for standard TCP) and to do linear recovery
at 7 segments per RTT increasing 8 segments per RTT
(rather than 1 per RTT for standard TCP).
The
resulting bandwidth for this 10 second transfer is 100 Mbs.
We also plot a line indicating what the cwnd recovery would have looked
like for standard TCP.
For this path, standard TCP would have taken over 45 seconds to reopen
cwnd to 1000 segments.
Additional plots related to this transfer are here.
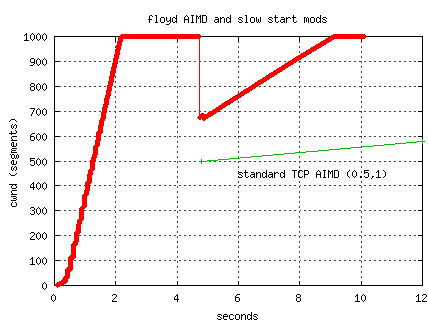
For comparison, we set up a simulation on ns-2 to compare Floyd's AIMD
and the standard AIMD. (We modified ns to use the modified multiplier
on the first loss.)
The ns-2 version uses a low-window of 31 (rather than the 38 in Sally's
draft) and for 1000 segment cwnd, the the decrement is 0.323949
and the additive increase is 8.6.
The following graph simulates the ORNL-NERSC path with a single drop
and no delayed ACKs.
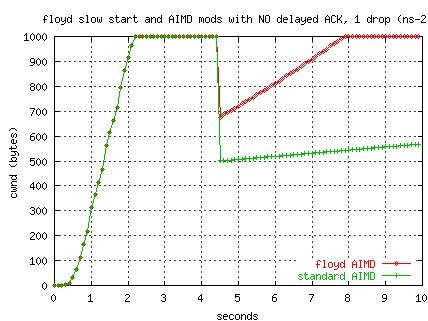
Our TCP tuning daemon, WAD, also does
AIMD pre-tuning.
The WAD can be preconfigured with AIMD values for a path, or can
use Floyd's equations to calculate an AIMD based on the buffer sizes
configured for the path.
The AIMD modifications are done just once, as compared with Floyd's
continuous update model.
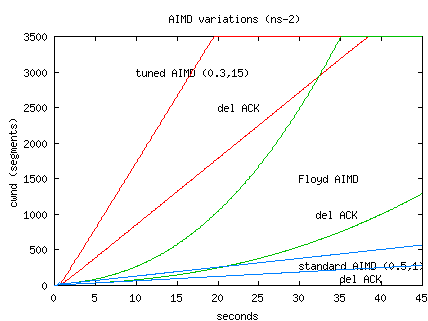
The following cwnd graph of an ns-2 simulation shows a packet loss early
in slow start for a 500 Mbs path with 80 ms RTT with maxiumum window set
at 3500 segments.
Standard AIMD is compared with Floyd's AIMD and a static pre-tuned AIMD (0.3,15).
Also compared are the algorithms with and without delayed ACKs.
Experiencing an early loss on this high delay, high bandwidth path
results in terrible performance for standard TCP AIMD.
This is a worst-case scenario, but packet loss in initial slow start
is all too common.
The number of seconds before the transmission rate reaches full bandwidth
after the early packet loss is summarized in the following table.
Using jumbo frames, 9000 byte MTU rather than 1500, performance is
improved by a factor of 6 for all algorithms.
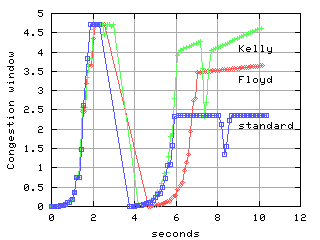
Tom Kelly's scalable TCP
uses a fixed AI recovery method with an MD of .125,
the following plot compares the performance of Kelly's TCP with Floyd
and standard TCP. The test is from California to Cern. Each flow
was run independently with a UDP blast injected at around 3 seconds
into each flow.