TCP auto-tuning zoo
More often than not, the bandwidth of a TCP flow is restricted by
the setting of the sender's and receiver's buffer sizes, and the flow
never utilizes the available bandwidth of the links.
Very few network applications provide the user with any way to tune
buffer sizes.
Some network utilities (ttcp, netperf, iperf) and a few FTP's (gridFTP)
allow the user (or network wizard) to specify buffer sizes, or disable
Nagle algorithms, assuming the user knows or can determine what the
optimal settings are.
Operating system default setting may limit the maximum values for some
of these tunable parameters.
System managers can change the default buffer settings for ALL connections,
but that usually is sub-optimal and wasteful of kernel memory.
Our current Net100
work and other recent work have looked at ways
of auto-tuning the buffer sizes for a particular flow.
(In Net100 we also consider tuning other TCP parameters for a particular flow.)
Here is a brief summary of auto-tuning work to date, starting with
network-aware applications and then kernel modifications to tune TCP flows.
NLANR FTP
NLANR has an auto-tuning
FTP that uses a train of ICMP or UDP packets to estimate the available
bandwidth and round-trip time between the client and server.
Using the bandwidth-delay product, buffer sizes are then set at the
client and server.
Enable tuning
Tierney et al. provide an API and network daemons that allow
one to modify a network application to query a daemon for the
optimal buffer size to be used for a particular destination.
For example, an FTP server and client might issue a call like
tcp_buffer_size = EnableGetBufferSize(desthost);
and then use that value to set the TCP buffer sizes.
The Enable daemons periodically measure the bandwidth and latency
of designated network paths and provide that information to client
as an RPC-like service.
It is also possible to generate scripts or command files that
would use tuning data from the Enable daemon to tune network applications
that accept tuning arguments.
Automatic TCP buffer tuning
In 1998,
Mathis et al describe modifications to a NetBSD kernel that allows
the kernel to automatically resize the sender's buffers.
(The receiver needs to advertise a "big enough" window.)
The kernel modifications allow a host that is serving many clients
to more fairly share the available kernel buffer memory and to provide
better throughput than manually configured TCP buffers.
For applications that have not explicitly set the TCP send buffer size,
the kernel will allow the send buffer to grow with the flow's
congestion window (cwnd) and utilize the available bandwidth
of the link (up to the receiver's advertised window).
If the network memory load on the server increases, the kernel will also
reduce the senders' windows.
So no modification are required to sending applications.
Dynamic right-sizing (DRS)
In 2001,
Feng and Fisk describe modifications to a Linux 2.4.8 kernel
that allow the kernel to tune the buffer size advertised by the TCP receiver.
The receiver's kernel estimates the bandwidth
from the amount of data received in each round-trip time and uses that
bandwidth estimate to derive the receiver's window.
The sender's window is not constrained by the system default window size
but is allowed to grow,
throttled only by the receiver's advertised
window.
(The liux 2.4 kernel allows the sender's window buffer to grow.
For other OS's, the sender would have to be configured with a "big enough"
buffer.)
The growth of the sender's congestion window will be limited by currently
available bandwidth.
High delay, high bandwidth flows will automatically use larger buffers
(within the limits of the initial window scale factor advertised by
the receiver).
No modifications are required to either client or server network applications.
Also see
Allman/Paxon
'99 paper on receiver-side bandwidth estimation.
In February, 2002, Fowler combined the Web100 and DRS patches into
the linux 2.4.16 kernel, and we did various testing over the wide area
network and our NISTnet emulator testbed.
For example, without DRS, a receiver taking the default window size (64K)
over a 100 mbs link (100 ms RTT) gets only 7 mbs, but with DRS
the TCP test get 68 mbs (for 5 second test).
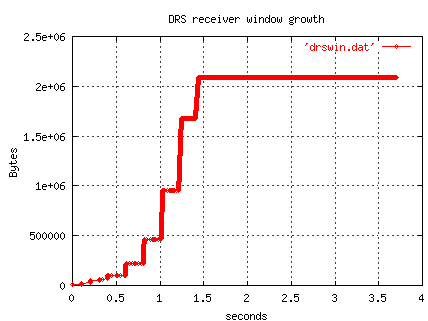
Here are some results from NISTnet showing the window advertised by
a DRS receiver for various bandwidths and 100 ms RTT (no losses).
Bandwidth(mbs) RecvWindow (bytes)
8 221440
16 482048
32 893184
48 2085120
64 3643136
Below is a plot of the advertised receiver window for the 48 mbs
test (100 ms RTT) from a tcpdump.
Another
DRS paper from LANL.
Linux 2.4 auto-tuning/caching
In 2001, the Linux 2.4 kernel included TCP buffer tuning algorithms.
For applications that have not explicitly set the TCP send and receive
buffer sizes, the kernel will attempt to grow the window sizes to match
the available bandwidth (up to the receiver's default window).
Like the Mathis work described above, if there is high demand for
kernel/network memory, buffer size may be limited or even shrink.
Autotuning is controlled by new kernel variables net.ipv4.tcp_rmem/wmem
and the amount of kernel memory available.
(See Linux 2.4 sysctl variables.)
Autotuning is disabled if the application does its own setsockopt()
for TCP's SND/RCVBUF.
Linux 2.4 doubles the requested buffer value in the setsockopt().
So if a receiver requests a 2MByte receive buffer, the kernel
will advertise 3143552.
Similarly, if a 128KByte send buffer is requested, cwnd can grow to 215752.
The Linux 2.4 kernel may also limit cwnd growth if the application
has over-provisioned socket buffer space.
Normally, TCP would keep increasing cwnd up to the minimum of
the sender's or receiver's buffer size.
If the application has requested more buffer space than the bandwidth-delay
product requires, then growing cwnd to fill this extra spaces causes
queueing at the routers and increasing RTT times.
Linux 2.4 moderates cwnd growth by increasing cwnd only if the
inflight data is greater than or equal to the current cwnd.
(One can observe this via the Web100 SlowStart counter, though
we're still not sure how/when/if this limit comes into play.)
The Linux 2.4 advertised receive window starts small (4 segments)
and grows by 2 segments with each
segment from the transmitter, even if a setsockopt() has been done
for the receiver window.
linux 2.4 receiver advertised window
segment window (scaled bytes)
2 8672
3 11584
4 14464
5 17376
6 20256
7 23168
8 26048
9 28960
10 31840
...
500 1571072
Thus the receiver window (memory) need only grow as large as the sender
requires.
Feng's DRS and Web100's autotuning use the receiver window to dynamically
control the sender's window and thence the sending rate.
However, small initial receive windows prevent the sender from sending a larger
number of initial segments during the initial slow start and
limits the effectiveness of "tuning" the slow-start increment during
initial slow-start.
Independent of auto-tuning,
The Linux 2.4 kernel has a "retentive TCP", caching (for 10 minutes)
TCP control information for
a destination (cwnd, rtt, rttvar, ssthresh, and reorder).
The cached cwnd value is used to clamp the maximum cwnd value for the
next transfer to that destination.
The cached ssthresh will cutoff the slow-start for the next transfer.
For high delay/bandwdith paths,
our experience has been that this feature tends to reduce the throughput
of subsequent transfers, if an early transfer experiences loss.
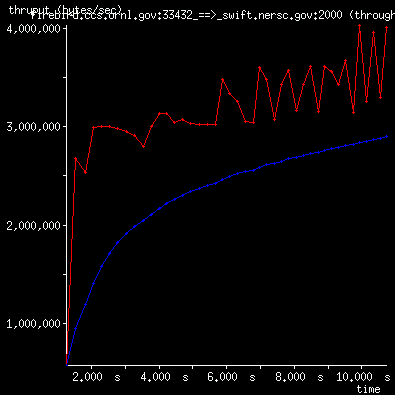
In the following bandwidth figure (xplot/tcptrace) sender/receiver are using
1 MB buffers and the transfer encountered no losses, but the graph
shows the transmission does not do a very aggressive slow-start.
Normally the red line (instantaneous throughput)
ascends rapidly in the first second.
So the data rate is growing very slowly in TCP's
linear recovery mode over this high delay/bandwidth
transfer (ORNL to NERSC).
We believe this is due to the setting of ssthresh
from the Linux 2.4 cache.
The /proc/net/rt_cache does not show the cached cwnd or ssthresh info (though
one can hack route.c to display ssthresh instead of window), but one
can see that caching is in effect by looking at the Web100 variables for
the flow.
The Web100 CurrentSsthresh variable would normally be infinite (-1) for a no-loss
flow, unless caching is in effect.
For this flow, CurrentSsthresh has a non-infinite value, even though
there have been no losses in this flow.
The cache can hold more than one entry for a destination, differentiated
by the TOS field.
Thus a telnet's buffer requirements will not affect an ftp's.
Root can flush the routing cache with
echo 1 > /proc/sys/net/ipv4/route/flush
but there doesn't seem to be a way to disable the caching.
(The latest Net100 extensions to the Web100 kernel mods provide a sysctl
variable to disable caching. 4/02)
The 2.4 autotuning/caching may be effective for big web servers,
but it can have an adverse effect on bulk transfers.
We also have had trouble with cwnd/ssthresh being cut by "resource
exhaustion" (device transmit queue overflows) in the sender (tcp_output.c).
This condition is reported as a SendStall by Web100.
We have experimented with increasing the device transmit queue size
(ifconfig txqueuelen, default 100)
and "disabling" the congestion event (WAD_IFQ).
Here are some results from an experiment between PSC and ORNL.
PSC issues ttcp -r -s -p 2000 -b 2000000 -f m
ORNL (100 Mbs) does ttcp100 -t -s -p 2000 -b 1000000 psc
txqueuelen Mbs SendStalls CongestionSignals CurrentSsthresh
100 58.8 6390 0 (SendStall disabled) 4294966376
now with SendStall enabled
100 20.87 4 1 182448
200 51.33 70 1 625536
400 55.83 14 1 737032
1000 63.44 0 0 4294966376
This graph shows the effect of SendStall on a transfer
from Amsterdam to Chicago (GigE, 100ms RTT).
The transfers are configured differently by the WAD.
There is also a NIC receive queue that is controlled by sysctl,
net.core.netdev_max_backlog (default 300),
that should also be increased by a factor of 10.
Linux 2.4 will also reduce or restrict the window size (Web100 calls
these OtherReductions) for SACK reneging ( ACK arrived pointing to a remembered SACK), moderated cwnd to prevent bursts, application limited ( cwnd
adjusted if not full during one RTO).
Linux 2.4 will do timeouts based on current RTO, and will do rate-halving
to sustain ACK clocking during recovery.
Linux 2.4 also does "speculative" congestion avoidance.
If a flow has entered congestion avoidance because of dup ACK's
or timeout, and the missing packet arrives "soon", then cwnd/ssthresh
will be restored (congestion "undo").
The reordering threshold (default 3)
will also be increased during the flow and cached at the end of
the flow.
Web100 instrumentation can track the DSACK's and growth of the retrans
threshold.
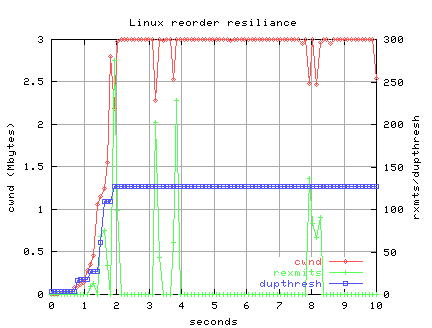
The following figure show that cwnd growth is nearly unaltered by
a periodic re-ordering of packets on the path from LBL to PSC.
Web100 reports 1487 packets re-transmitted during this 10 second
iperf TCP test, but also reports 1487 DSACK's
received, so all retransmits were unnecessary (packets were out of order
not lost), and Linux responds to the DSACK's by undoing the congestion
avoidance, thus sustaining high throughput.
The Web100 instruments report 10 congestion events, but the
ssthresh is stil "infinite", indicating no real losses.
To see how a more conventional TCP stack suffers in the face
of reordering, visit our atou experiments.
Finally, Linux 2.4 has number of tests for disabling delayed ACKs (quickack).
During initial slow-start delayed ACKs are disabled until the full
receive window is advertised.
Since the receive window grows by 2 segments per received packet,
delayed ACKs are disabled for the first half of initial slow start.
No delayed ACKs should improve the speed of slow start, but we also
suspect it may be causing losses in slow-start for GigE interfaces
where the burst-rate gets too high for some device in the path... maybe.

Net100 auto-tuning daemon
In 2001, the Web100 project
provided kernel modifications to the Linux 2.4 kernel and a GUI
to tune the TCP buffer sizes of network applications.
In 2002, as part of our Net100 project
we developed a daemon
(WAD)
to use the Web100 API to tune client/server TCP
send and receive buffers, AIMD, slow-start, etc. for designated flows.
Like the Enable project described above, the daemon can use
latency and bandwidth data to calculate optimum buffer sizes.
Other interesting tuning issues include possibly using parallel streams,
multiple paths, or modifying other TCP control parameters.
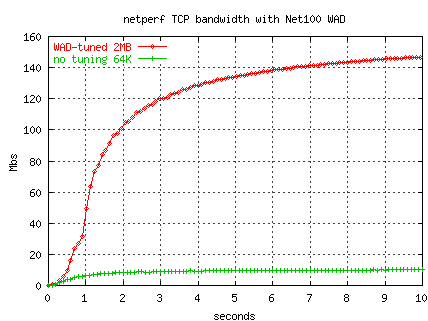
Here is a comparison of a network-challenged application, compared
to a hand-tuned and WAD-tuned version.
Learn more about WAD here.
Web100 auto-tuning
In the fall of 2002, the Web100 kernel was extended to support a DRS-like
auto-tuning as part of
John Heffner's senior thesis on
autotuning
using Web100 (directed by Matt Mathis).
Web100 autotuning can be enabled for all flows with a sysctl or
can be tuned by the WAD on a per-flow basis.
This auto-tuning ignores setsocket() options by the application
and disassociates application network buffers from the kernel's
TCP buffer needs for a flow.
The flow's TCP buffers will be controlled by the receiver's
advertised window and will grow in proportion to the bandwidth-delay
product estimated by the receiver.
other auto-tuning
In 2003, Dovrolis
and others are developing the SOBAS protcol that does receiver-side
socket buffer sizing at the application layer.
The TCP bulk transfer stream is augmented by a UDP stream to allow
the receiver to measure RTT and loss rate and calcuate a bandwidth-delay
product buffer size that hopefully achives the "maximum feasible
throughput".
Other ?
OpenBSD/FreeBSD saved ssthresh/cwnd info for a path in the kernel
routing table, as I recall?
That info could be used to "prime" subsequent connections on the same path.
Reference ?
Also
TCP Westwood
is a sender-side only modification of the TCP Reno protocol stack
that optimizes the
performance of TCP congestion control using end-to-end
bandwidth estimation (from ACKs) to set congestion window
and slow start threshold after a congestion episode.
Also TCP Vegas does sender-side
cwnd adjustments to avoid losses.
Links
Visit the network performance links page
for RFC's and papers.
See LANL's Weigle's
A Comparison of TCP Automatic Tuning Techniques for Distributed Computing
2002
Last Modified
thd@ornl.gov
(touches: )
back to Tom Dunigan's page
or the net100 page.