 EES Benchmarking -- recent results
EES Benchmarking -- recent results
EES Benchmarking -- recent results
EES Benchmarking -- recent results
 Evaluation of Early Systems Project
Evaluation of Early Systems Project
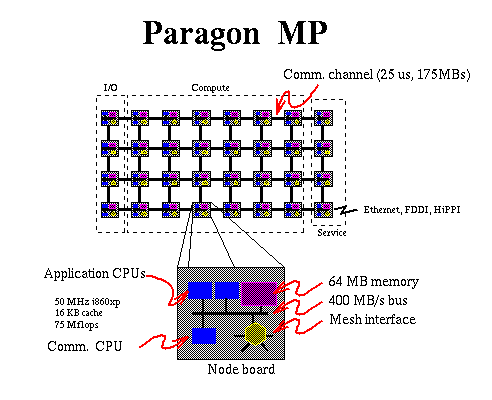
 Paragon MP
Paragon MP
As part of our evaluation of early systems, we have been benchmarking prototypes of Intel's new Paragon MP system. Each node contains two application processors and a communication processor, so the MP is both a message-passing and shared-memory multiprocessor. We have measured both message-passing performance and shared-memory performance of the Paragon MP (Dunigan, ``Beta Testing the Intel Paragon MP'', ORNL/TM-12830, 1995). Other benchmarks measure performance of message-passing paradigms commonly found in scientific applications as well as network and I/O performance. Benchmarks have also been used as part of the acceptance criteria for the 2048-processor Paragon MP XPS-150 recently delivered to ORNL's Center for Computational Science ( CCS ). Message passing latency has been measured at 28 microseconds, and bandwidth for a one million byte message was measured at 154 megabytes/second. Linpack performance achieved 80.5 gigaflops on 2048 processors.
Latency and bandwidth
Message passing performance is usually measured in units of time or bandwidth (bytes per second). In this report, we choose time as the measure of performance for sending a small message. The time for a small, or zero length, message is usually bounded by the speed of the signal through the media (latency) and any software overhead in sending/receiving the message. Small message times are important in synchronization and determining optimal granularity of parallelism. For large messages, bandwidth is the bounded metric, usually approaching the maximum bandwidth of the media. Choosing two numbers to represent the performance of a network can be misleading, so the reader is encouraged to plot communication time as function of message length to compare and understand the behavior of message passing systems.
As part of our benchmarking research over the last ten years, we have measured latency and bandwidth over most multiprocessors and local area networks. The following figure illustrates the relative communication performance of various message-passing systems.

Parallel I/O
Many parallel applications require high bandwidth I/O. Our benchmarks evaluate the performance of parallel I/O systems under various configurations and loads. The Intel Paragon system includes a parallel file system and high-performance I/O libraries.
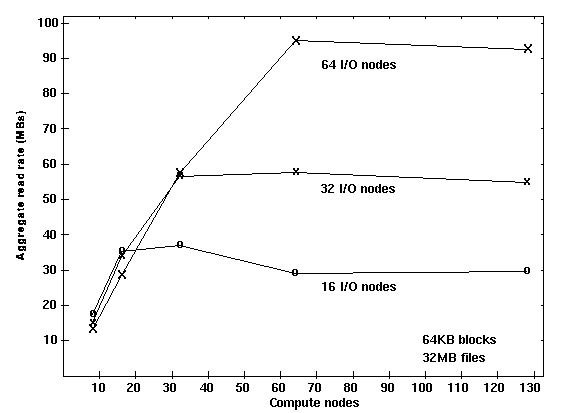 Aggregate read throughput of Paragon Parallel Files System (PFS)
with varying number of compute nodes and I/O nodes.
From Dunigan,
``Beta Testing the Intel Paragon MP'',
ORNL/TM-12830, 1995 (204KB)
Aggregate read throughput of Paragon Parallel Files System (PFS)
with varying number of compute nodes and I/O nodes.
From Dunigan,
``Beta Testing the Intel Paragon MP'',
ORNL/TM-12830, 1995 (204KB)
Shared-memory multiprocessors
The Paragon MP architecture uses message passing between node boards and shared memory among the processors on a node board. Our beta testing program included evaluation of serial number one of KSR's shared-memory multiprocessor, so we have used many of the benchmarks we developed for the KSR in evaluating the Paragon MP. The benchmarks measure memory contention, lock and synchronization performance, and the performance of various application kernels.
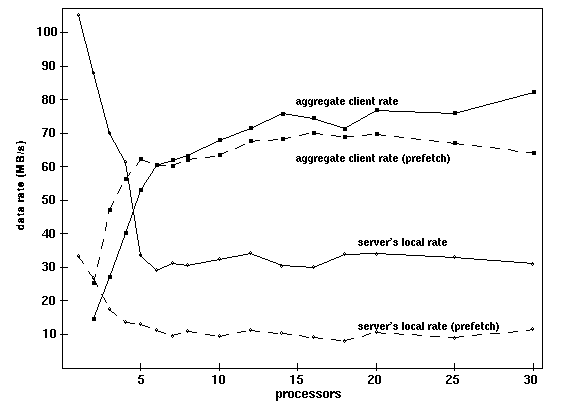 Aggregate data rate for multiple KSR processors faulting independent
data from a single KSR server processor.
From Dunigan,
``Multi-ring performance of the KSR'',
ORNL/TM-12331, 1994 (291KB)
Aggregate data rate for multiple KSR processors faulting independent
data from a single KSR server processor.
From Dunigan,
``Multi-ring performance of the KSR'',
ORNL/TM-12331, 1994 (291KB)
{kind=link}