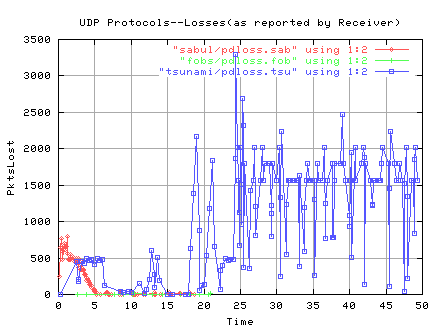
Figure 1. Losses as reported by the receiver
1. Introduction
Why is the speed at which data is transferred over networks
seemingly not keeping up with the touted improvements in the hardware
through which this data travels??
We have optical networks limited only by the speed of light, 10GbE switches,
and multiple, hyperthreaded Ghz processors inside our computers.
Yet it is a verifiable fact that today's applications are having trouble
delivering needed thruput even as network bandwidth increases and hardware
--both inside and outside our own computers--increases in capacity and power.
Here at Oak Ridge National Laboratory we are particularly interested in
improving bulk transfers over high-bandwidth, high-latency networks because of our
involvment in storage and in the transfer of data for cutting-edge scientific
applications. It is important to remember however that aggressive
tools, such as the ones described in this review and including parallel TCP,
are intended for high-speed, dedicated links or links over which quality of
service is available--not for general use over the broader Internet!
2. Background
2.1. Tuning TCP
ORNL has looked at many ways to address this problem. Extensive
tests
have been conducted
attempting to pinpoint problems and suggest possible solutions for
the "fixable" problems found.
We are partners in the NET100 /
WEB100 project
which is an effort
to look "inside" the kernel by expanding the kernel instrumentation
set and making these kernel variables available for reading/tuning
through the linux /proc file interface.
We have written and modified a number of tools which make use of this newly accessible
information--the WAD,
iperf100, ttcp100, WEBD, TRACED,
and a web100-enabled bandwidth tester .
We have also simulated TCP
using the TCP-over-UDP test harness, atou , so that we might see the effects of
changes to TCP proposed by Sally Floyd and others.
The claim is that TCP, which has been the workhorse of the past, is a part
of the problem in today's high-bandwidth, high-latency networks primarily because
some of the very algorithms which have served it well in the past are unable
to keep the pipe full
when the bandwidth is high, round trip times are long, and there is often
re-ordering/loss in the path.
Slow Start is the way TCP initiates data flow across a connection. Congestion
Avoidance is the way TCP deals with lost packets. Congestion Avoidance and Slow
Start require that two variables be kept for each connection--a congestion
window(cwnd) and a slow start threshold size(ssthresh).
Slow Start operates by
observing that the rate at which new packets should be injected into the
network is the rate at which the acknowledgments are returned by the other end.
Because of this, when round-trip times are long, much more time elapses before
the capacity of the path is reached. TCP continues to double cwnd for each ACK
received until a timeout occurs or duplicate ACKs are received indicating a lost
packet.
Upon receiving 3 duplicate ACKs, cwnd is halved and that value is stored
in ssthresh. If there is a timeout, cwnd is reset to 1 or 2 segments.
If cwnd is less than or equal to ssthresh, TCP is in Slow Start; else Congestion
Avoidance takes over and cwnd is incremented by 1/cwnd for each ACK. This is
an additive increase, compared to Slow Start's exponential increase. Again,
a flow is penalized when round-trip times are long and the large capacity of the
path may never be reached.
Some researchers have concluded that the
solution requires a new, udp-like protocol. NETBLT, a transport level
protocol, has been proposed to permit the transfer of very large amounts of
data between two clients. NETBLT is designed to have features which
minimize the effects of packet loss, delays over satellite links, and network congestion.
2.2. NETBLT
NETBLT is a bulk data transfer protocol described in rfc998 and
proposed in the 1985-87 timeframe as a transport level protocol
having been assigned the official protocol number of 30. NETBLT
is included in the background section because at least two of the
newer UDP protocols have acknowleged their debt to the
design of NETBLT and the design of a third is clearly based on
the NETBLT ideas. However the resistance to new
kernel-level protocols plus the lengthy approval process seems to have
influenced the authors of the new UDP protocls to implement their
designs at the application-level.
NETBLT was designed specifically for high-bandwidth, high-latency
networks including satellite channels. NETBLT differs from TCP
in that it uses a rate-based flow control scheme rather than TCP's
window-based flow control. The rate control parameters are negotiated
during the connection initialization and periodically throughout
the connection. The sender uses timers rather than ACKS to maintain
the negotiated rate. Since the overhead of timing mechanisms
on a per packet basis can lower performance, NETBLT's rate control
consists of a burst size and a burst rate with burst_size/burst_rate
equal to the average transmission time per packet. Both size and rate
should be based on a combination of the capacities of the end points
as well as that of the intermediate gateways and networks.
NETBLT separates error control and flow control
so that losses and retransmissions do not affect the flow rate.
NETBLT uses a system of timers to ensure reliability in delivery
of control messages and both sender and receiver send/receive
control messages.
rfc998 gives the following explanation of the protocol:
"the sending client loads a buffer of data and calls down to the
NETBLT layer to transfer it. The NETBLT layer breaks the buffer
up into packets and sends these packets across the network in
datagrams. The receiving NETBLT layer loads these packets into a
matching buffer provided by the receiving client. When the last
packet in the buffer has arrived, the receiving NETBLT checks to
see that all packets in that buffer have been correctly received.
If some packets are missing, the receiving NETBLT requests that
they be resent. When the buffer has been completely
transmitted, the receiving client is notified by its NETBLT layer.
The receiving client disposes of the buffer and provides a new
buffer to receive more data. The receiving NETBLT notifies
the sender that the new buffer is ready and the sender prepares and
sends the next buffer in the same manner."
As described, the NETBLT protocol is "lock-step". However, a
multiple buffering capability together with various timeout/retransmit
algorithms give rise to the claim that NETBLT gets good
performance over long-delay channels without impairing performance
over high-speed LANs. NETBLT, however, is not widely implemented.
3. Recent UDP application level protocols
The following protocols have not yet been described in an rfc as
far as could be determined so the overview of each is taken from
papers or documentation produced by the authors of the protocols.
In some cases, where descriptions did not seem clear or documentation
was sketchy, we did look at the code for further clarification.
These protocols are still in transition. This means, among
other things, that the details which follow are a snapshot in
time and not a final picture.
SABUL, RBUDP,
FOBS and TSUNAMI
all address the problem
of limited thruput over high-speed, high-bandwidth networks with proposals
which are similar in concept but slightly different in implementation.
RBUDP(QUANTA) will not be evaluated at this time. QUANTA has some
very interesting ideas such as forward error correction but has
not implemented this and does not yet do file transfers as it is still in the
very early stages of development.
3.1. Use of TCP/UDP channel(s)
All three proposals use one or more TCP connections for sending/receiving
various control information and one UDP connection for
sending/receiving the actual data. Once the connections are established,
the control packets are sent from receiver to sender for SABUL and
TSUNAMI but control packets are sent both ways in FOBS . For all
three, the data is sent only one way--from sender to receiver.
3.2. Rate-Control Algorithm
Rate control is seen as a way to control the burstiness so
often observed in TCP flows. This burstiness may cause losses as
router queues suddenly fill up and packets are dropped or
network interface cards cannot keep up. Also, rate control allows
a flow to more quickly fill a pipe without going through the
initial ramping-up process characteristic of TCP.
Rate control or inter-packet delay,
which adjusts to packet loss and/or network congestion as reported by
the receiver, has been
added in some form to all the UDP protocols to counter the charges of
unfair use of capacity and potential to create network problems.
....rate calculation...
TSUNAMI gives the user the ability to
initialize many parameters including UDP buffer size,
tolerated error rate, sending rate and slowdown/speedup
factors with the 'set' command. If the user does not set sending rate
however, it starts out at 1000Mbs with a default tolerated loss rate
of 7.9%. Since a block of file data(default 32768) is read and
handed to UDP/IP, the rate control is actually
implemented per block rather than per packet.
The receiver uses the combination of the number of packets received
(a multiple of 50) and a timed interval (>350ms) since the last
update to determine when to send
a REQUEST_ERROR_RATE packet containing a smoothed error rate.
If the error rate is greater than the maximum tolerated rate, the
sending rate is decreased; if it is less, the sending rate is
increased.
FOBS asks for the local and remote network interface card speed which
it uses to determine a maximum beginning rate. The default tolerated
loss rate is 1%. FOBS calculates a table of rates during sender
initialization linking these rates to a network state machine.
After a segment of data(about 10000 1466-byte packets) has been
transferred, the sender requests an update from the receiver. The
reported packet loss from the receiver is used then to calculate the
current bandwidth. The current bandwidth is compared against the
pre-calculated table values to determine the current state of the
network and pull a corresponding rate from the table.
SABUL begins with a preset IPD (inter-packet delay) of 10 usec which it
converts to CPU cycles. The receiver generates a SYN packet based on
a timed interval(200ms) which signals the sender to use both the number
of lost packets and the number of packets--including retransmits--sent
since the last SYN time to calculate a current loss rate. This
loss rate is then input to a weighted moving average formula to
give a history-rate. If the history-rate is greater then a preset
limit(.001), the IPD is increased; if less than the limit, the IPD
is decreased; if equal, .1 is added. In a former release, SABUL
attempted to keep the loss rate between an upper and lower limit.
The latest implementation is similar in concept to TSUNAMI's in that both
keep the delay between blocks/packets between an upper and lower limit.
...rate implementation...
SABUL is the only one of the three to implement the IPD(inter-packet
delay) between individual packets as opposed to groups of packets.
The delay is implemented by repeated calls to rtdsc() until the
requisite number of clock cycles have passed. FOBS checks the
sending rate after a burst of packets(25) and implements the delay
with a gettimeofday calculation until time to send the
next burst. TSUNAMI uses a timed select() to implement the delay
between blocks of data.
4. Test Results and Analysis
conditions of the tests
The tests were run morning and afternoon over a period of several months.
The results varied widely and so the ones included are members of
best/worst case scenarios. Tests were also run using NISTNET for a
sanity check since we did not have access to simulator code for the
protocols.
characteristics of the computers at each end
On the ORNL side, firebird is a Dell Precision 330 single-processor host
running a 2.4.20-web100 linux
kernel with a SysKonnect Gigabit Ethernet network interface card
connected to a Fast Ethernet network(CCS 192 LAN).
Firebird has a 1.4GHz Intel Pentium IV processor, a 24GB Maxtor hard
drive and 512MB of memory.
Tests indicate speeds of approximately 4400Mbs+ writing to and
12000Mbs+ reading from disk.
net100.lbl.gov is a single processor host
running a 2.4.10-web100 linux kernel with a
NetGear|GA630 Gigabit Ethernet interface card connected
to a Fast Ethernet network. net100.lbl has a
AMD Athlon(tm) 4 Processor stepping 02 running at 1.4GHz
and 256MB of memory.
Tests indicate speeds of approximately 73.276Mbps+ writing to and
47.9Mbps+ reading from disk.
characteristics of network between
The results of ping tests:
ping -c 10 131.243.2.93Running traceroute shows use of the ESnet OC48 backbone with basic route symmetry although variations can occur.
round-trip min/avg/max/mdev = 67.209/67.490/67.657/0.324 ms ffowler@net100(145)>ping -c 10 160.91.192.165
rtt min/avg/max/mdev = 67.287/67.748/68.219/0.333 ms
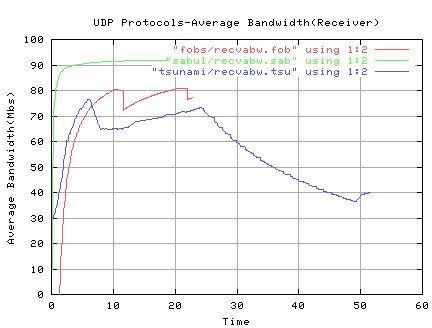
ORNL to LBL: Application Rate(Mbs) Loss/Retrans/PktsSent/PktsRecv/Dups BEST CASE *QUANTA 358.28 73/ 73/ 137742/ 137669/0 FOBS 317.17 2816/ 6720/ 143147/ 138436/2009 SABUL 343.49 15/ 15/ 140015/ 140005/5 **TSUNAMI 307.23 55/ 259/ 13361/ 13102/204 ***iperf 489.0 0/ 0/ 145499/ 145499/0 iperf100 -P 3 279.7 6/ 6/ 171303/ 171299/2 LBL to ORNL: WORST CASE *QUANTA 310.37 4415/ 4415/ 142157/ 137742/0 FOBS 256.17 2170/ 6103/ 142530/ 138484/2057 SABUL 151.76 47838/ 44895/ 184895/ 142441/2441 **TSUNAMI 243.92 1689/ 1689/ 14963/ 13330/228 ***iperf 420.0 3/ 0/ 142846/ 142843/0 iperf100 -P 3 229.8 5/ 7/ 145491/ 145484/2 *QUANTA, as shipped, does not adjust the rate even if there are losses! **TSUNAMI was giving 16384 byte blocks to ip and letting ip fragment ***iperf does not buffer nor retransmit losses and so should be fasterTSUNAMI does not provide a memory-to-memory transfer option so the file accesses--fseek, fread, fwrite--were commented out for this test.
Application Rate(Mbs) Lost/NewDataSent/PktsRcvd/Dups BEST CASE FOBS+ 45.01 2668/ 146421/ 151624/5203 SABUL 52.14 5463/ 146220/ 178297/32077 TSUNAMI* 47.17 44400/ 146419/ 181840/35421 GRIDFTP 33.79 (4224.00KB/sec) 3 streams WORST CASE FOBS 28.52 3503/ 146421/ 147787/1366 SABUL 37.25 4200/ 146220/ 216482/70262 TSUNAMI* 8.2--had to Ctrl/C GRIDFTP 13.12 (1638.31KB/sec) 1 stream *TSUNAMI was sending 1466 byte blocks +FOBS would have achieved 243.4Mbs if not counting the wait for file writes!! QUANTA does not have a file transfer option at this timeFile transfers to pcgiga at Cern gives a longer RTT with the following results:
BEST CASE
Application Rate(Mbs) Lost/Retrans/PktsSent/PktsRcvd/Dups
iperf 469.0 0/ 0/ 147563/ 147563/0
FOBS 247.78 78/ 14188/ 160609/ 155792/9371
SABUL 250.88 3/ 3/ 146223/ 146222/2
TSUNAMI 270.74 0/ 4980/ 146419/ 146901/482
WORST CASE
FOBS 153.03 23/ 14245/ 160666/ 156133/9712
*SABUL 139.52 1708/ 91856/ 238076/ 191202/44982
TSUNAMI 4.30--had to Ctrl/C
*SABUL had 4 EXP events in which all packets "in flight" are assumed
lost
4.3. Tests using a LAN, a private network and NISTNET
To validate results obtained over the broader Internet where conditions
are unpredictable and constantly changing, tests were performed under
more controlled conditions using NISTNET.
NISTNET is running on an old, slow Gateway machine, viper, with 64MB of
memory and two 100Mbs Network Interface cards. One NIC is connected into
a NETGEAR Fast Ethernet Switch and one into a local area network. The
other two machines involved are dual processor pcs previously
used in a cluster and have 512MB of memory and a 100Mbs Network Interface
card. Pinto is connected into the same local area network and pinto10
is connected into the NETGEAR Switch. Conditions are not completely
controlled in the local area network, but are observed to be mostly
stable with rare exceptions.
With NISTNET configuration:
pinto.ccs.ornl.gov pinto10 --delay 35.000 pinto10 pinto.ccs.ornl.gov --delay 35.000pings from pinto to pinto10 gave the following:
[ffowler@pinto ffowler]$ ping -c 3 10.10.10.2 round-trip min/avg/max = 70.5/70.7/71.0 ms [ffowler@pinto10 ffowler]$ ping -c 3 160.91.192.110 round-trip min/avg/max = 70.6/70.6/70.6 ms4.3.1. NISTNET Memory-to-Memory Transfers
Application Rate Lost/Retrans/PktsSent/Dups iperf(TCP) -P 3 78.8 Mbits/sec 7/ 7/ 150571/0 iperf (UDP) 90.5 Mbits/sec 0/ 0/ 153849/0 FOBS 80.8 Mbits/sec 1/ 143/ 136570/142 QUANTA 89.9 Mbits/sec 0/ 0/ 137742/0 SABUL 87.1 Mbits/sec 37480/ 17843/ 157823/2832 *TSUNAMI 83.1 Mbits/sec 0/ 1/ 13103/1 *1 16K block is about 12 packetsThe results of 200MByte(+/-) memory-to-memory tests with NISTNET configuration:
pinto.ccs.ornl.gov pinto10 --delay 35.000 --drop 0.0107
pinto10 pinto.ccs.ornl.gov --delay 35.000 --drop 0.0107
Application Rate Lost/Retrans/PktsSent/Dups iperf(TCP) -P 3 44.9 Mbits/sec 20/ 20/ 159662/0 iperf(UDP) 90.4 Mbits/sec 17/ 0/ 153849/0 FOBS 79.3 Mbits/sec 16/ 1215/ 137642/1199 QUANTA 87.5 Mbits/sec 15/ 15/ 137727/0 SABUL 83.5 Mbits/sec 47744/ 14172/ 154172/4230 *TSUNAMI 82.5 Mbits/sec 18/ 18/ 13151/49 *18 16K blocks are about 12*18 = 216 packets 13151 16K blocks are about 12*13151 = 157812 packets 49 16K blocks are about 12*49 = 588 packets4.3.2. NISTNET File Transfers. For real file transfers over the NISTNET testbed from pinto to pinto10, NISTNET was configured as above. The file transferred is 214649928 bytes. The drop rate--a little over .01%--consistently results in 16 to 20 packets being dropped. This is confirmed by results from FOBS which reported 17 lost packets, iperf-UDP reported 16 packets lost and iperf-TCP reported 20 packets lost.
A summary of the results from file transfers using NISTNET are shown in the table below:
Application Rate Lost/Retrans/PktsSent/PktsRecd/Dups FOBS* 71.4 17/ 4754/ 151175/ 150537/4116 SABUL** 87.2 11544/ 19911/ 166131/ 148317/2097 TSUNAMI*** 33.2 181210/ 207317/ 354961/ 176184/29765 *FOBS sends 1466 byte data packets **SABUL sends 1468 byte data packets ***TSUNAMI was configured for a blocksize of 1466 bytes so comparisons could be made with the other two protocols but as shown in the tables above, TSUNAMI gets better thruput when using a larger block size and letting IP fragment--this is partly because TSUNAMI is written so that "blocksize" controls not only the size of the blocks sent but also the size of the file reads and writes.4.3.3. Analysis of LAN test results
delay = ((sending-time + 50) < ipd_current) ? (ipd_current - delay - 50)) : 0;A select() call is used to implement the delay.
5. Summary Comparison of Protocol Features
|
PROTOCOL COMPARISONS |
||||
|---|---|---|---|---|
| Features | Sabul | Tsunami | Fobs | |
| TCP Control Port | Yes--Control packets are sent from receiver to sender The sender can also generate and process a pseudo control packet upon the expiration of a timer |
Yes--Control packets are sent from receiver to sender | Yes--2 control ports are used Control packets are sent both ways |
|
| UDP Data Port | Yes--Data is sent from sender to receiver | Yes--Data is sent from sender to receiver way | Yes--Data is sent from sender to receiver | |
| Threaded Application | Main thread does file I/O 2nd thread keeps track of timers and sends/receives packets |
Server forks a process to handle receiver's request Receiver creates a thread for disk I/O |
The sender and receiver are NOT threaded fobsd is but was not used for these tests |
|
| Rate Control | Yes--Inter-packet delay implemented by continuous calls to rtdsc() | Yes--Inter-block delay implemented by calls to gettimeofday() and select() | Yes--Inter-block delay implemented by continuous calls to gettimeofday() | |
| Tolerated Loss | 0.1% | user can set--7.9% default | 1.0% | |
| Authentication | No | Yes--via a shared secret | No | |
| Packet Size | No | Yes--via a shared secret | No | |
| Socket Buffers | No | Yes--via a shared secret | No | |
| Congestion Control | No | Yes--via a shared secret | No | |
| Reorder resilience | No | Yes--via a shared secret | No | |
| Duplicates | No | Yes--via a shared secret | No | |
| Diagnostics | No | Yes--via a shared secret | No | |
6. Observations
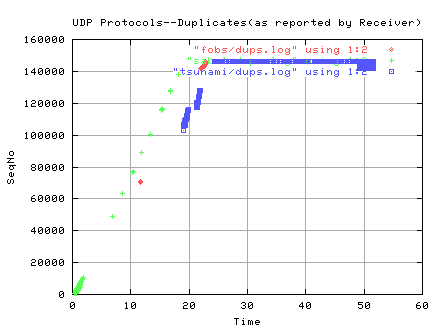
TSUNAMI, SABUL and FOBS all do well as long as there is little reordering or
loss. Reordering and/or loss seem to cause them all to transmit
uneeded duplicates. FOBS gives priority to new data and transmits a
CHUNK(default 100MB) of data before doing retransmits. TSUNAMI and SABUL
give priority to requests for retransmits. The SABUL client reports any missing
packets immediately as well as periodically every 20ms. The TSUNAMI client
reports missing packets after the requirements for numbers of packets
received (a multiple of 50) and amount of time since the last report
(more than 350ms) have been satisfied.
In addition, TSUNAMI continues to retransmit the last
block/packet until receiving a REQUEST_STOP from the receiver. In one
short, loss-free transfer from ORNL to LBL of 8,135 blocks/packets of size
1466, the last block was observed being transmitted 11,876 times. The
client actually received 7,835 of the 11,876 before it quit.
REQUEST_RESTART requests seem to cause instability. When
REQUEST_RESTARTs are sent by the receiver, often both sender and
receiver had to be manually stopped as both somehow seemed
to get confused and the rate fell below 4Mbps. This happened regularly on
transfers from ORNL to LBL with files of 100mb or more. The
message, "FULL! -- ring_reserve() blocking" also appeared at the client
regularly during the transfer of large files. In order to complete the
necessary file
transfers with TSUNAMI, the retransmit table was enlarged and a block size
of 16384 used in an attempt to eliminate REQUEST_RESTART requests.
FOBS also transmits many unecessary packets. In a file
transfer involving 146,421 data packets(214649928 Bytes) and no losses,
FOBS actually sent 150,100 packets. These packets are apparently sent while
the sender is awaiting instructions from the receiver telling it what needs
to be done next. In this case, after sending the first chunk,
packets 70000-71229
were re-transmitted. Similar re-transmissions occurred after the second and
third chunks. The receiver read all
71527 packets in the first chunk, sent a COMPLETEDPKT and got ready
for the next chunk. Before reading the first packet in the next chunk,
packets 70000-71229 were read and thrown away.
A 'scaleFactor' is used to keep the packets in synch with the correct
iteration or the receiver might assume these retransmits are
part of the next chunk.
SABUL also has problems when there is significant reording/loss. Since
the client reports every perceived loss immediately, this can mean a
lot of control packets. In one case, the sender was observed having to
deal with one control packet for almost every data packet it was sending.
Since a tabulation of lost packets is also sent every 20ms, the same loss
may be reported more than once and the sender will count it again for rate
control purposes which gives rise to an interesting phenomenon. If the
tabulation of losses for the last period is greater than the number
of packets sent during the same period, the sender solves the problem by
assuming 100% loss for that period.
With a shorter RTT--this scenario was with 150 usecs--perhaps not
as many unecessary packets would be sent but it is assumed these UDP
protocols are meant for transferring large files on high-bandwidth,
high-delay networks.
After much testing and studying,
it is still not clear why SABUL and TSUNAMI report so many losses.
One clue may be that the protocols that wait 10000 packets(FOBS) or
more(iperf & quanta) to report losses do much better. That would
seem to indicate that packets may not be received in strict order
but more study needs to be done on this problem.
6. Conclusions
fairness
TCP/Internet friendly??
Possibly...Possibly not...SABUL is the only one
that makes any real claims of fairness.
The efficiency and fairness of SABUL's rate-control algorithm is
discussed in
Rate Based Congestion Control over High Bandwidth/Delay Links.
TCP friendliness is defined as: "A protocol P is TCP friendly if the
coexisting TCP connections share approximately the same amount of
bandwidth as if P is a TCP connection." The paper presents charts
of experiments done to show that SABUL is TCP friendly and therefore
fair.
The paper, An Analysis of SABUL Data Transfer Protocol presents the results of NS2 simulations involving multiple
SABUL connections and also multiple SABUL and TCP connections. The
conclusions reached using their model are that:
limitations
The UDP protocols were basically designed to work over networks with
high bandwidth, long delay and little or no loss or reordering. With the
possible exception of SABUL, they were not meant to share bandwidth
fairly with other streams but were designed to run in reserved slots where
they could run as fast as the hardware and routers involved will allow.
As results show, at present they do not have the "smarts" for dealing
effectively with loss or reordering.
TCP rising to the challenge?
As mentioned, there is a lot of work going on in an effort to "spruce up"
TCP to meet today's demands. One one of the topics under consideration
is the size of the maximum transmission unit(MTU). Matt Mathis at the
Pittsburgh SuperComputing Center is providing proposals for discussion . Also, Stanislav Shalunov discusses the virtual
MTU.
Using rate-based rather than window-based transmittal of packets means
the UDP protocols do not have to "ramp-up" at the beginning nor "cut
the window in half" when a loss is perceived. There is ongoing work,
however, to experiment with modification of these aspects of TCP with
Sally Floyd's
proposals for TCP with large congestion windows
and Tom Kelly's scalable TCP algorithm.
future planned tests
Since these tests were done, new versions of SABUL and its derivative,
UDP-based Data Transport Protocol(UDT), have been developed; a new version of
QUANTA/RBUDP has been
made available; implementations in user space and the linux kernel of Datagram
Congestion Control Protocol(DCCP) are available for download. We hope to
look at these new implementations under a variety of conditions and particularly
with tests planned on the new ???...Have Steven write a few words about the tests he and Nagi have planned...