 Optimizing bulk transfers over high latency/bandwidth nets
Optimizing bulk transfers over high latency/bandwidth nets
Optimizing bulk transfers over high latency/bandwidth nets
Optimizing bulk transfers over high latency/bandwidth nets
At ORNL, we are interested in high speed bulk data transfers between NERSC and ORNL over ESnet (see CCS bandwidth and the Probe testbed). This is a high-bandwidth (OC3 to OC12) and high latency (60 ms round-trip time (RTT)) scenario, where TCP's congestion avoidance can greatly reduce throughput. We are interested in choosing buffer sizes to reduce loss and in developing more aggressive bulk transfer protocols, yet still respond to congestion. We are looking at ways to monitor and tune TCP and also considering a congestion-controlled UDP (TCP friendly) that could do partial file write's with lseek to keep the buffers drained, and then fill holes as dropped packets are retransmitted (SCTP and multicast FTP protocols use this technique). The UDP TCP-like transport would also serve as test-harness for experimenting with TCP-like controls at the application level similar to TReno. We are also evaluating TCP tuning with Web100 as part of our Net100 project.
An alternative transfer mode could use streaming (rate-based) transport of the whole data set, followed by retransmission of missing segments. In addition, one could use parallel transfer streams, overlapping timeouts/retransmissions between streams to get increased throughput as proposed by Rao at ORNL and demonstrated by SLAC (though whether this or streaming is "fair" to the net is debatable, see RFC 2914). Parallel streams can provide a larger "virtual MSS" which provides faster startup and faster recovery.
NOTE The following text has not yet been updated with in-line citations, but there is much related work.
Baseline
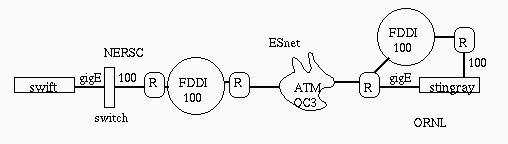
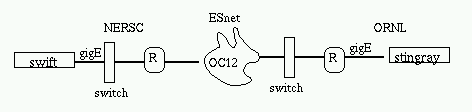
Our throughput is not going to be any better than the slowest component, so our first objective was to establish a baseline of performance for I/O and network for the two Probe test machines (stingray and swift). Both machines run AIX 4.3, though stingray has an updated TCP stack. Figure 1 illustrates how the two machines are connected. Stingray has two paths to swift, one via Ethernet/100 through ORNL's local routers and external FDDI ring, and a more direct path over Gigabit Ethernet directly to the ESnet router at ORNL. In the Spring, 2001, the ESnet backbone is ATM/OC3 provisioned as UBR. Other ESnet sites share the bandwidth in this ATM cloud.
The NERSC machine, swift, is connected from its GigE interface through a switch to the local firewall router and FDDI and then to the ESnet router. The MTU's of the GigE interfaces is 1500 bytes. The FDDI MTU is 4470, and the ATM MTU is 9180.
We have access to the ORNL routers and the ESnet router at ORNL (but not at NERSC, sadly). The routers are using FIFO queuing. By looking at the router statistics before and after one of our experiments, we can see if queues were overflowed or cells dropped. (The ATM interface at the ESnet ORNL router shows a steady loss rate of 35 frames per million, though none of these may be associated with the path between ORNL and NERSC. More recent measurements show that rate improving to 3 frames per million.)
We tested the TCP throughput rate on the local network for the GigE interface on stingray for both standard Ethernet frames (1500 bytes) and jumbo frames (9000 bytes). For comparison, throughput for the 100 Mbs Ethernet interface is included. Tests were performed with stingray and eagle (AIX) and falcon (Compaq) using ttcp (64K read/write's) and netperf.
The wide-area connection is over ESnet's ATM network. From an earlier network study, we hava available at ORNL a Linux PC with ATM interface and a set of loopback PVC's at various ATM switches at ORNL, UT, and NERSC. We measured ATM throughput and latency (RTT) for various AAL5 frame sizes. The ESnet backbone carries IP segments over AAL5 frames. For an OC3, the peak bandwidth of IP over ATM is about 135 Mbits/sec. Minimum local loopback RTT for 40-byte packet is 0.1 ms, and 57.2 ms when looped back at NERSC. As best we could, we also measured throughput via the loopbacks.
The ATM tests indicate that full OC3 bandwidth is available (some times), but our TCP/IP testing is limited by the 100 Mbs FDDI ring at NERSC and ORNL (and by competing traffic). Minimum UDP latency between NERSC and ORNL was measured at 58 ms for an 8 byte datagram. UDP rate-controlled (no loss) tests between ORNL and NERSC yielded 87 Mbs (to ORNL) and 84 Mbs (to NERSC) using 1460-byte UDP datagrams (best case). On a Sunday afternoon, UDP rates reached 96 Mbs, though only 87 Mbs over stingray's 100E (stingray.ccs.ornl.gov).
TCP throughput is the target of this study, and TCP's characteristics are discussed in detail later in this report. We have measured peak bandwidth of 90 Mbs with ftp and ttcp between NERSC and ORNL, but sustained bandwidth is often much less than this.
Ultimately, we are looking at doing file transfers between ORNL and NERSC, so we also measured the I/O throughput of the AIX machines. From looking at the source code for ftp and ftpd (SunOS, linux, wu-ftpd, and kerberos/ftp), file I/O (and network I/O) are done with 8K read/write's (10K for kerberos ftp). We ran a simple file write test then file read test using 8K records for various file sizes on stingray (/ssa/scratch1). The write rate is a little pessimistic because it includes sync/close time.
Besides local and ESnet network testing, we also did network testing over a VBR-provisioned ATM/OC3 link to UT, over a cable modem (with peak rate limits), ISDN, and dialup. Local area testing included Ethernet (10/100), GigE (also with jumbo frames), FDDI, and GSN (HiPP2). We tested our TCP-like transport on AIX, Sun OS, Linux, Freebsd, IRIX, DEC/Compaq UNIX, Solaris, Sun OS, and Windows.
TCP tutorial
TCP provides a reliable data stream over IP. IP is a packet-based protocol, where packets can be lost, duplicated, corrupted, or arrive out of order. TCP uses sequence numbers, checksums, positive acknowledgements, and timeouts/retransmissions to provide a reliable data stream. TCP is used for most of the Internet services, mail, http, telnet, and ftp.
For our study, we are concerned with bulk transfers, and for bulk transfers, TCP will try to send the data in MSS-sized packets. MSS, maximum message size, is negotiated when the TCP connection is established. The MSS should reflect the minimum MTU of the interfaces comprising the path. ( Path MTU discovery can be used by the hosts to find the appropriate MSS.) The MSS for our NERRC-ORNL studies is usually 1460. Part of our study considers larger segment sizes, though the TCP user usually has little control over MSS. Sending data segments larger than the MTU cause IP to fragment the segment, and IP fragmentation usually hurts network performance.
TCP uses a sliding-window protocol to implement flow control. The receiver advertises his receiver window, the maximum number of bytes he can currently accept. The transmitter must not send more data than the window permits. Both transmitter and receiver must reserve buffer space equal to this window size. The operating system has a default window size, but the application program can change this value. The window size is the most critical parameter affecting TCP performance, yet many applications do not support a way for changing this value.
The window size should be equal to the product of the round-trip time times the bandwidth of the link. The default window size for most OS's is 16K or 32K bytes. For high bandwidth, high-delay links, this is usually inadequate. For example, for a RTT of 60ms on a 100Mbs link, if the receiver has a 16K window, the maximum throughput will be only 266 KBs! To reach full bandwidth on this link, the receiver needs to have a window of 750KB. (The sender also needs a 750KB buffer because he must buffer all data until it is acknowledged by the receiver.) This reveals another problem for the user, the size of the window field in the TCP packet is only 16-bits. To support window sizes larger than 64 KB, the OS must support window-scaling, a relatively new TCP option. The web100 project is an effort to provide the user with applications and OS's that support the latest TCP features. For our AIX systems, window-scaling is supported, but it must be enabled. Unfortunately the stock AIX ftp does not have a way to request window size. As we will see, picking the proper window size is critical to TCP performance.
Prior to 1988, TCP senders would usually blast a window-full of data at the receiver. Van Jacobson noticed that this was leading to congestion collapse on the Internet. TCP was modified to provide congestion avoidance. When a sender started up (slow start), it would send one segment (MSS), and then send one additional segment for each ACK, until the receiver's window was reached or a packet was lost. (Slow-start grows the window exponentially.) Cwnd was used to keep track of this collision window. If a packet was lost, detected by a time out or three consecutive duplicate ACK's, the transmitter would halve cwnd saving the value in ssthresh, resend the "lost" packet (fast retransmit), then set cwnd to one and go through slowstart again til it reached ssthresh. After reaching ssthresh, the sender would increment cwnd only once per round-trip time (congestion avoidance phase,linear). Thus TCP tests the link for available bandwidth until a packet loss occurs and then backs off and then slowly increases the window again. This additive-increase-multiplicative-decrease converges in the face of congestion and is fair. (TCP's notion of fair is that if N TCP flows share a link, each should get about 1/Nth of the bandwidth.)
The most widely deployed implementation of TCP is Tahoe. Tahoe added delayed ACK's -- the receiver can wait for two segments (or a timer) before sending the ACK, this can slow both slow-start and congestion avoidance since both are clocked by incoming ACKs. Tahoe also added fast retransmit, rather than waiting for a timeout to indicate packet lost, when the transmitter receives three duplicate ACK's, it resends the lost packet.
More recent enhancements to TCP were called Reno, NewReno, and SACK. Reno adds fast recovery to fast retransmit, once the collision window allows, new segments are sent for subsequent duplicates ACKs. NewReno handles multiple losses within a window and partial ACKs. SACK has the receiver send additional information in its ACK about packets that it has received successfully. This way the sender can re-send missing segments during fast retransmit and move the left-edge of the window. When recovery is exited, often an ACK is received cumulatively acknowledging a large number of packets, this can allow the sender to transmit a burst of packets. See the links page for papers/RFCs describing the various TCP stacks.
So the performance a user sees from TCP will be sensitive to the window size, the TCP stacks, and the packet loss. We will investigate TCP's performance in the results section of this report, but first let's review some of the tools we used and developed.
Tools
For analyzing TCP behavior, we used ttcp, a public domain C code that allows one to choose amount of data, record lengths, and most importantly send/receive buffer sizes (which, in turn, control the offered TCP window). To test available bandwidth we developed a rate-based UDP program and an ATM version. Netperf offers similar capabilities, and iperf can exercise parallel TCP streams. Dan Million also modified the AIX/Kerberos ftp client and server to support setting the size of the send/receive buffer.
Tcpdump was used to capture packets flows, and a tcptrace and xplot were used to plot and summarize the tcpdump data sets. We also had access to packet traces from ORNL's intrusion detectors.
We also developed a TCP-like UDP transport protocol. Its default operational mode is equivalent to TCP-Reno, with a NewReno congestion control option. In April, 2001, Florence Fowler added support for SACK/FACK including rampdown. This parameterized and instrumented transmitter/receiver permits us to alter the TCP-like parameters without needing kernel access.
Most of the studies of TCP performance make extensive use of the ns simulator. We found this simulator useful as well, allowing us simulate the same behavior that we were observing in our tests of the ORNL-NERSC link. The simulator also has many variations of TCP, so we can evaluate various speedup techniques through simulation and through our TCP-like UDP transport program.
OC3 Results
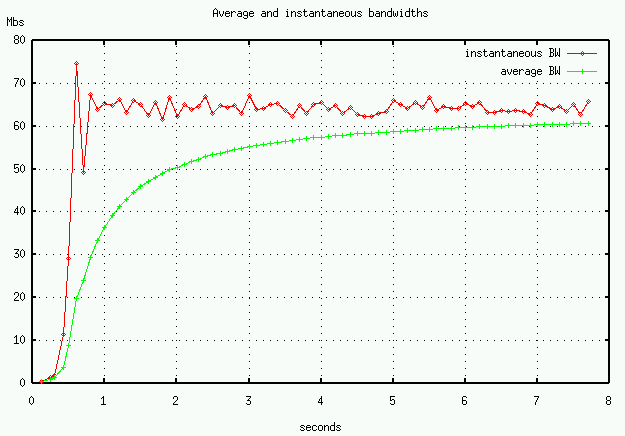
We conducted various experiments between swift and stingray, using different buffer sizes, different TCP options within AIX, and different interfaces. We evaluated both TCP and our TCP-like UDP transport. Figure 2 illustrates the throughput behavior of a TCP flow with no loss. (Actually, the data was collected from our TCP-like UDP transport.) TCP (and our TCP-like UDP protocol) starts with a small window and then exponentially increases it until loss occurs or the available bandwidth or receiver's window size is reached. As can be seen in the figure, in less than a second, available bandwidth is reached. The rate or time to reach peak can be calculated analytically as well, since one additional segment (MSS-sized) is transmitted for each ACK received, which takes one round-trip time. We can't do anything about the round-trip time, so if we wish to improve the startup performance we need to have a larger MSS or try a larger initial window size. (See the links page for papers on increasing the initial window size. Our UDP transport has options for increasing the MSS and initial window size.) TCP reaches a steady-state, the transmitter is regulated by the ACK arrival rate. Note that it takes many seconds over our ORNL-NERSC path to reach capacity.
The startup rate can be slowed by a factor of two if the receiver utilizes delayed-ACKs (sending an ACK for every other segment received). Most TCP-stacks utilize delayed ACKs, our UDP transport does not so enjoys a slightly faster startup rate.
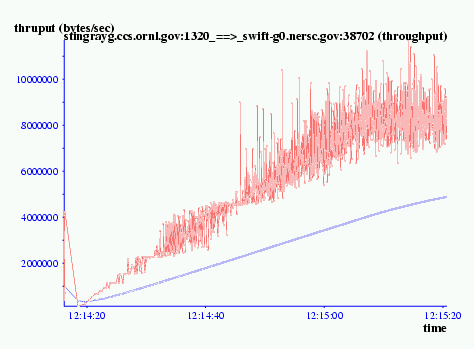
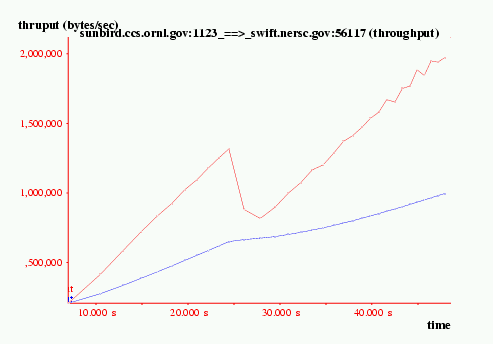
Figure 3 illustrates what can happen if packets are lost during a transfer. The figure shows the ftp transfer of 334 MB file from ORNL to NERSC utilizing a 1 MB window. (Dan Million modified the AIX ftp server and client to support setting window sizes.) The data rate reaches 9 MBs, but the losses keep the average rate to under 4 MBs.
Packets are dropped early in the startup, and results in a TCP timeout. (AIX was running in Reno-mode for this test, so multiple drops within a window result in a timeout.) We have observed that drops in the startup phase are common, because the packets can be generated in bursts, and TCP can try to send up to twice the peak during startup. Recall, that TCP halves its collision window on a drop. Multiple drops shrink the collision window further.
|
Rate of Recovery
During recovery, TCP adds one MSS per RTT, so in one second
there are n RTT's, n= ceiling(1/RTT).
The number of bytes transmitted in that second is
|
The packet loss at the 72 second mark illustrates the two phases of TCP's recovery. TCP starts with a small window after a loss and increases exponentially til ssthresh is reached, and then climbs linearly (congestion avoidance). Notice that it takes more than 50 seconds to recover from the loss phase at the 18 second mark. The slope of this line can be calculated analytically from the MSS and the RTT, and is proportional to MSS/(RTT*RTT) -- see sidebar. To improve this recovery rate, one either needs a bigger MSS or a larger additive increase in the recovery algorithm. (TCP adds one new segment per RTT.) Using our UDP transport or the simulator, we can experiment with altering this increment. (Increasing the increment turns out to be "fair", because as it is, if multiple TCP flows are sharing a link and there is congestion, they all halve their rates, but the nodes nearer (shorter RTT) will get more of the bandwidth than the distant node. See papers on links page.) As with startup, a delayed-ACK receiver also slows down the linear recovery.
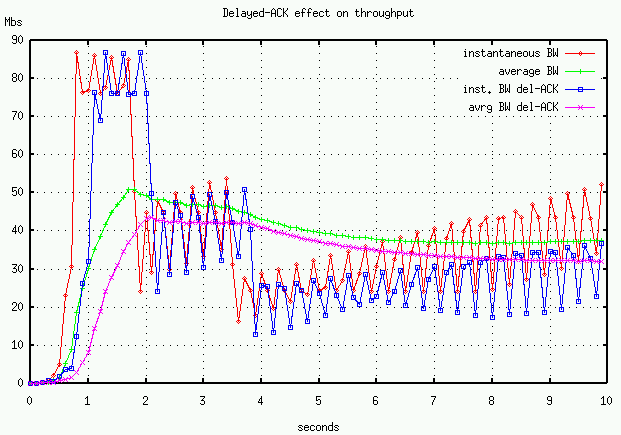
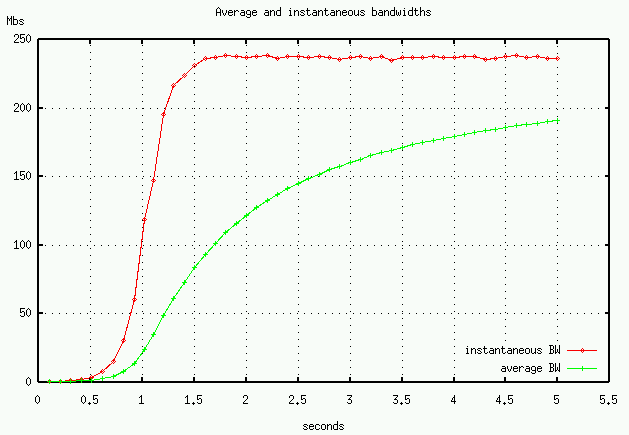
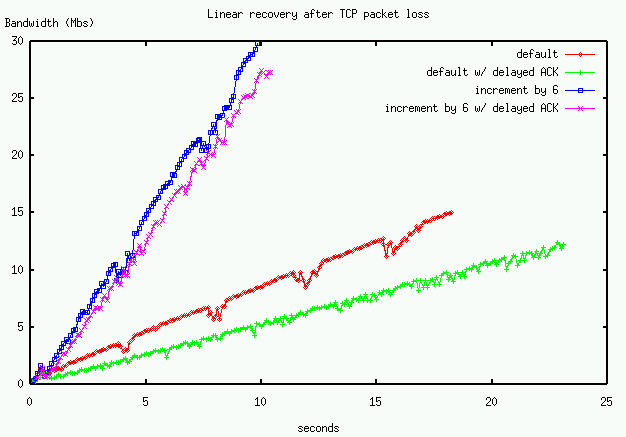
Our TCP-like UDP transport can optionally use delayed ACK's but it is difficult to see the effect with Internet measurements (though see the example on our TCP over UDP page). However, using the ns simulator we can illustrate the effect of delayed-ACK's on throughput. Figure 4 shows average and instantaneous throughput of a TCP transfer with and without delayed ACK's. The simulation mimics our ORNL-NERSC link, a 100Mbs link with 60 ms RTT. Two packets are dropped in the simulation.
As can be seen, the delayed-ACK slows both the startup and recovery phases of TCP.
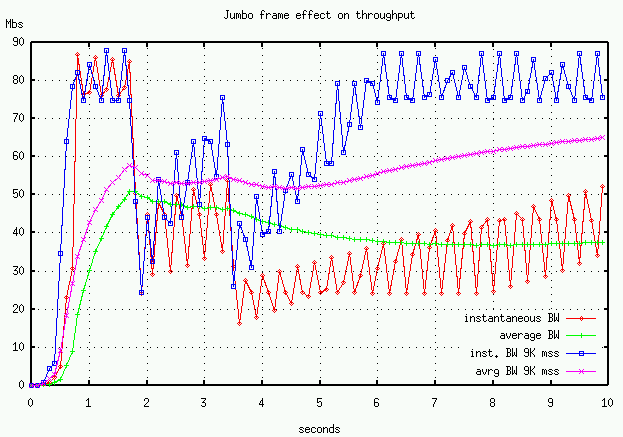
Using this same simulation configuration, Figure 5 compares average and instantaneous throughput for an Ethernet-sized segment (1500B) versus a jumbo-frame segment (9000B). As noted earlier, both startup and recovery times are effected by the segment size. ATM supports a 9K segment size, and FDDI supports a 4K segment, so if both endpoints had different network interfaces and the intervening path supported the larger segment size, then throughput should be improved.
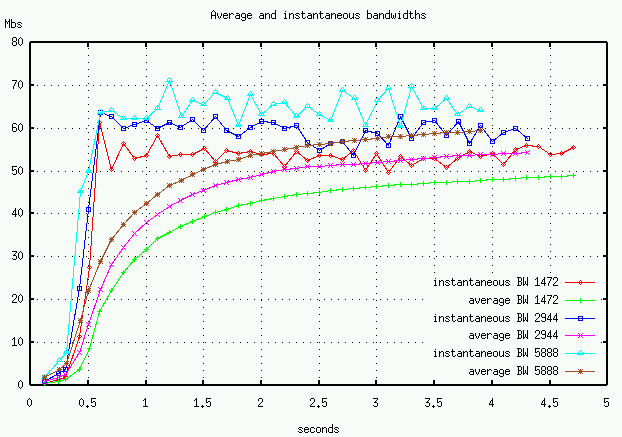
We have some evidence from our ATM tests, that these larger segments might experiences a higher cell loss rate. However, we used a larger MSS (2944 and 5888 bytes) with our UDP transport and got better throughput. For the same number of bytes transferred and the same effective window size we got 50 Mbs with 1472-byte datagram, 55 Mbs with 2944-byte datagram, and 58 Mbs with 5888-byte datagram. (Figure 6) The UDP datagrams greater than the 1500-byte Ethernet MTU are fragmented by IP. These larger datagrams have an effect similar to TCP's delayed-ACK, in that all fragments (MTU-sized) have to arrive before the receiver ACK's the datagram. Kent and Mogul, however, argue that IP fragmentation usually lowers network performance. The same performance improvement may be gained by using a "virtual MSS" and avoid IP fragmenation, see our atou tests.
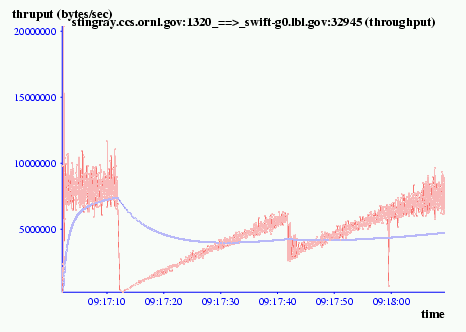
The simulated flow in Figures 4 and 5 mimics the behavior of an actual FTP transfer from ORNL to NERSC illustrated in Figure 7. Figure 7 is an xplot of a tcptrace analysis of a tcpdump of a file transfer using a 512KB receive window. Two packets losses were encountered, and the peak rate fluttered about 9 MBs.
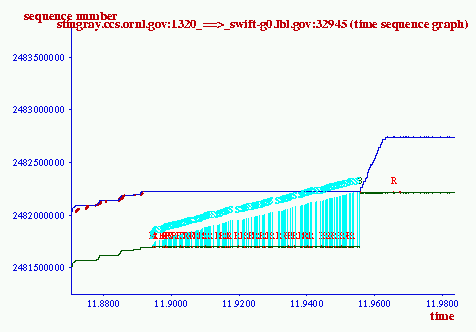
Figure 8 illustrates how xplot can be used to zoom in on the first loss at time 09:17:11. The transmitter sending rate is regulated by the receiver's window when the loss occurs, indicated by the straight ACK line. Both machines had SACK enabled, so the duplicate ACK's carry SACK (S) information. There's only one lost packet, so SACK has no benefit in this case. the lost packet is transmitted after 3 duplicate ACKs, and the ACK arrives at 11.96 and re-opens the window for transmission.
If we're lucky we get no packet losses or only a single drop, but even a single drop over a high-delay, high-bandwidth link can drastically reduce throughput. If the single loss occurs during slow-start ( Figure 3 and Figure 9), the effect on throughput is even worse. Early packet losses are common because of the bursts in slow-start
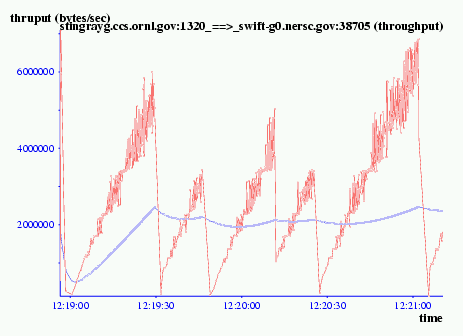
TCP often exhibits periodic loss behavior. If the receiver's window is greater than the available bandwidth and the intervening router's have limited buffer space, then TCP's behavior is illustrated in Figure 10. TCP experiences a loss, backs off and linearly increases its window, testing for available bandwidth until it experiences a loss, and then restarts the sequence again. Figure 10 is an FTP from ORNL to NERSC using an 800KB window. A larger increment or segment size does not help much with periodic loss. The larger size speeds recovery, but the loss rate increases too.
We can try to improve TCP startup and recovery with bigger initial windows, larger increments, or smart acknowledgements, but it would be better if we could avoid loss all together. Constant rate-based UDP transports are used for audio and video streams and proposed for Multicast FTP over a LAN. The transmitter selects a transfer rate and blasts away, ignoring losses or, for MFTP, transmitting lost packets later. We have used streaming UDP and ATM/AAL5 to estimate link capacity and loss. Such streaming protocols are unfair, TCP flows competing with the streaming flows graciously backoff. TCP Vegas made an effort to estimate available capacity based on measured throughput for each window and thus reduce its rate and avoid losses. (More recently ECN has been proposed to help TCP stacks backoff before a drop actually occurs.) Estimating capacity and implementing rate-based output is difficult (especially for high-bandwidth links). TCP Vegas also doesn't fair well when the other TCP stacks are non-Vegas, since Vegas backs off early, the other TCP flows grab more and more of the available bandwidth.
Parallel flows have been used by web browsers to speed up page downloads, by overlapping the slow-start of concurrent TCP connections (persistent TCP connections are also used in later HTTP implementations). Making k TCP connections from a TCP application takes advantage of TCP's "fairness", giving the application k/N of the available bandwidth. Cottrell suggests using parallel TCP connections for bulk transfer as well. Using iperf, we have experimented with parallel transfers from ORNL to NERSC. Although TCP's slow-start is exponential, with a long RTT and delayed ACK's, it can take considerable time to reach full bandwidth. For ORNL-NERSC, it can take nearly a second and 1.5M bytes. So if one is sending a number of small files, sending them in parallel should improve aggregate throughput. The following table shows aggregate throughput for a one or more 3 MB TCP transfers from ORNL to NERSC. (When this test was conducted, something was limiting peak bandwidth to NERSC to 50 Mbs.) The receiver window is conservatively configured at 60K bytes as well as larger window sizes.
For larger transfers, the startup time is less a factor, but parallelism may still provide higher throughput. The following table is for 10 second iperf TCP transfers from ORNL to NERSC for various window sizes.
OC12 Results
In June, 2001 the link between NERSC and ORNL was upgraded from OC3 to OC12 and the FDDI bottlenecks were eliminated.
(See current ESnet topology.) The test machines were connected with GigE interfaces. However, routing was changed to route traffic through New Mexico, raising the RTT from 60 ms to 101 ms. (This increase in RTT is a bad thing since TCP's linear recovery rate is proportional to MSS/(RTT*RTT).) Using iperf we reached 400 Mbs with UDP rate-based tests. (This is probably limited by the speed of the NERSC test machine.) With TCP we have achieved only 100 Mbs to NERSC from ORNL, but with 5 MB buffers, we reached 183 Mbs for a 10 second netperf test. The following figure shows the throughput of a transfer from NERSC to ORNL without any packet losses.
Such error free performance has been rare. Also the ORNL OC12 interface was initially unstable, crashing the router under heavy loads.
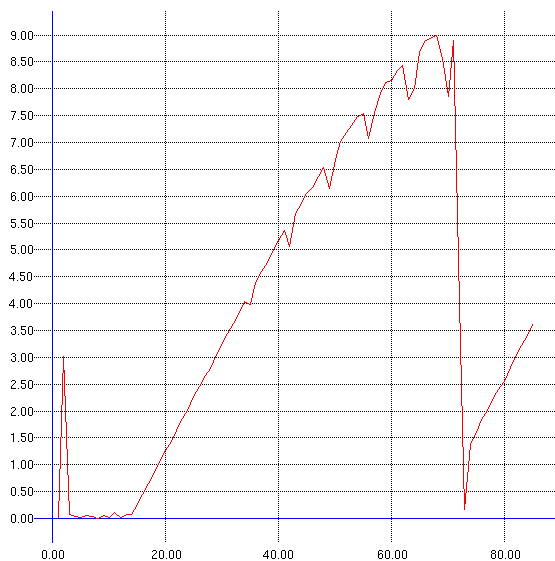
Packet loss is still common on the OC12 link due to congestion or under-provisioned routers. The following figure shows the devastating effect of packet loss during startup and the slow linear recovery (0.5 Mbs) over the 102 ms roundtrip link between NERSC and ORNL. The bandwidth only reaches 10 Mbs after 60 seconds.
A shorter RTT would help the slope of this recovery, or a larger MSS (jumbo frames?). With our TCP-over-UDP we can adjust the congestion avoidance recovery parameters. The following graph shows the effect of default recovery with and without delayed ACKs versus adding 6 to the collision window on each RTT. The TCP-over-UDP test harness was configured to drop packet 20 for the these tests between NERSC and ORNL.
In July, we still are getting less than 50 Mbs from TCP over the OC12 from/to ORNL-NERSC (most of the time). The NERSC-to-ORNL path sometimes has done 60 seconds worth of tests without loss. Using iperf in 10 second, UDP mode, we tried to find a data rate at which we would get no losses for 10 seconds.
In August, 2001, with some router fixes we have achieved loss-free one-way, UDP transfers between NERSC and ORNL up to 300 Mbs. We have seen up to 184 Mbs with TCP, the following table shows the actual and theoretical (buffersize/RTT) TCP throughput between NERSC and ORNL. These are 10 second netperf tests, and in 10 seconds TCP achieves only about 90% of maximum when the RTT is 100 ms.
Here are some results from an August 8, 2001 HPSS migration/staging test between ORNL and NERSC, illustrating NIC speed mismatch and the effects of idling the TCP flow. Similar results were reported by King at SC2000 in Parallel FTP Performance in a High-Bandwidth, High-Latency WAN.
Summary
To sustain high throughput over a high delay/bandwdith link using TCP or a transport with TCP-like congestion control, one needs to avoid loss and recover fast if loss occurs. We investigated several ways to
To achieve high throughput with TCP between NERSC and ORNL, it is important that the application be able to control the initial window size. Choosing the optimal window size is problematic, because one wants to avoid packet losses yet be close to the available bandwidth. Recovery from losses and throughput is affected by the TCP options selected in AIX, and in general, SACK will give the best performance. Increasing the initial window size had only a modest effect on performance of the NERSC-ORNL transfers. Increasing the increment on congestion avoidance speeds recovery at a slight risk of causing additional loss. A large MSS would improve startup and recovery times and reduce interrupt load, but our ATM data suggests that a bigger MSS might be more likely have dropped cells. We also experimented with large UDP datagrams (up to 4KB), letting IP do fragmentation and reassembly and got better throughput. There is some concern that a larger datagram might be more susceptible to ATM cell loss. More study is needed on the effect of a large MTU/MSS. Loss can also occur from packet bursts following recovery or after an idle period.
The vendors' interpretation of the TCP specs and and implementation can affect TCP performance. We found two bugs in the AIX TCP stack that reduced throughput. We have yet to do extensive experiments with our SACK/FACK and Mathis's "rampdown" smoothing of cwnd during congestion in our TCP-like UDP implementation. The effect of our burst control and initial ssthresh were inconclusive.
Using the Internet for tests is beneficial in that we are able to observe actual loss patterns (single drops, bursts, periodic, etc.), but evaluating protocol optimizations over the Internet is problematic. We cannot be sure if the behavior we measure is a result of our protocol changes or to the different traffic experienced in the test. Simulation and emulation need to be a part of any protocol optimizations.
Stingray's direct GigE connection to the ESnet router provided higher loss and lower throughput than the Ethernet100 interface. We could not discern if the loss was occurring in the ATM cloud or at the NERSC ESnet router. We suspect that burst losses are occurring because the GigE interface generates those bursts so fast it overruns the buffers of the switch/router that must slow down the flow into NERSC's 100 Mbs FDDI.
Streaming and parallel flows can provide higher throughput, but are not fair. Constant-rate UDP flows can avoid slow-start and recovery, but since they don't respond to congestion, their use should be restricted to private nets. Parallel TCP flows can take advantage of TCP's fairness, by giving one host/application more "votes". Parallel flows from parallel hosts may be needed to fill multigigabit links, and concurrent flows from a single host application can overlap TCP start-up delays and recovery, but should be restricted to private nets. (See links on parallel flows and congestion collapse.)
Future work
Links
Visit the network performance links page for tools, RFC's and papers. Also learn more about ORNL's TCP over UDP and web100 exerperiments as part of our Net100 project.
{kind=link}