The cumulative ACK is just like TCP's, with optional delayed ACK support.
As part of our Net100 and Probe efforts in improving bulk transfers over high speed, high latency networks, we have developed an instrumented and tunable version of TCP that runs over UDP. The UDP TCP-like transport serves as a test-harness for experimenting with TCP-like controls at the application level similar to TReno. It is not a full transport protocol that one could use as the basis for a file transfer program (though we may consider that in the future). The implementation provides optional event logs and packet traces and can provide feedback to the application to tune the transport protocol, much in the spirit of Web100 but without the attendant kernel modifications. Part of the motivation for developing such a test harness arose from bugs in the AIX TCP stack.
The experimental UDP protocol includes segment numbers, time stamps, selective ACKs, optional delayed ACKs, sliding window, timeout-retransmissions with rate-based restart, bigger initial window, bigger MSS, burst avoidance, congestion avoidance (but more aggressive, experimenting with initial window size and AIMD parameters). The protocol continues to transmit on the first dup ACK's (limited transmit, RFC3042). The test harness consists of a configurable client (transmitter) and an ACK-server (receiver). The transmitter supports Reno, NewReno, and SACK/FACK and more recently HS TCP, scalable TCP, and TCP Vegas. (For a quick review of TCP, visit our bulk transfer page.
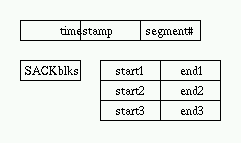
The protocol header includes timestamp and segment number.
The receiver's header includes the transmitter's timestamp,
the segment number of the last good contiguous segment and
up to three optional two-word blocks of SACK info.
The cumulative ACK is just like TCP's, with optional delayed ACK support.
A simple configuration file controls the transmitter. The following aspects of the transmitter can be configured:
The transmitter behaves like TCP with Reno, Newreno, or SACK/FACK using slow-start and congestion avoidance. Upon termination a summary of the configuration and session statistics are printed as below.
With a debug level of 4 or higher, a trace file is produced for each transmit and ack packet, data includes time stamp, segment number, round-trip time, congestion window, and threshold.
Depending on the debug level, events (timeouts, retransmissions, etc.) are loggged on stderr.
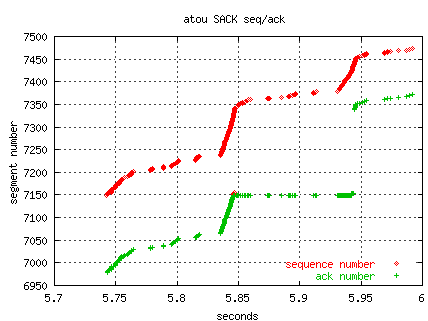
The following two excerpts contrast NewReno and SACK.
The data sets for the plots are created from the trace file (debug 4).
The example below shows a packet loss at time 2.22, and five other
losses within the same RTT.
NewReno sends a few new packets when after cwnd is halved, then
gets a partial ack, and retransmits packet 2225 after one RTT (95 ms),
and then retransmits packet 2227 after another RTT, and so on.
So full recovery (2.83) takes over six RTT's.

By starting multiple clients and servers (using different port numbers for each pair). you can even do some parallel stream experiments. The TCP-like UDP transport also can make good round-trip estimates from the time stamps. Most TCP stacks use a coarse (0.5 second) resolution timer for estimating round-trip time, and TCP times only one packet per round-trip time. The TCP estimates are complicated by retransmissions and delayed/cumulative ACKs. Newer TCP implementations support a time-stamp option. From analysis of the time-stamp data for our UDP protocol over the ORNL-NERSC link, we chose to initially implement a simple one-second timeout. (Timeouts are rare, and packet loss is usually detected by multiple duplicate ACKs.)
Vegas
In 2002, we (Tom Dunigan and student Ashraf Jahangeer)
added TCP Vegas-like options to atou.
Each RTT, Vegas calculates the difference (delta) of the
expected throughput and actual throughput.
Vegas compares this delta with preset thresholds (alpha, beta, gamma),
and exits slow start if gamma is exceeded, and adjusts cwnd
depending on delta's relation to alpha and beta during
congestion avoidance
Though Vegas with small values of alpha/beta/gamma doesn't compete well
with standard congestion algorithms on the same link, we are interested
in experimenting with larger parameter values for high delay/bandwidth
paths.
Most of the previous work with Vegas has been through simulation.
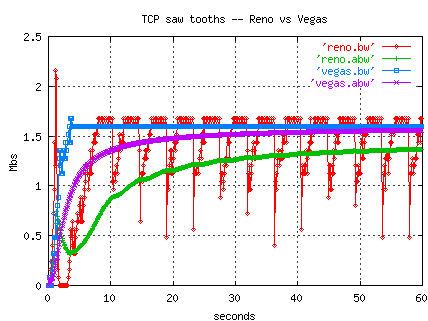
Below is a plot from an ns simulation
of TCP Reno continually experiencing losses (insufficient
router buffer space) and exhibiting the classic sawtooth performance,
yielding only 75% of the link's capacity.
In contrast, TCP Vegas avoids losses in this case and throughput reaches
the link capacity
(The flows weren't competing, they each were simulated independently
for 60 seconds, 1.6 Mbs link, 100 ms RTT, delayed ACKs.)
Our atou Vegas allows us to configure alpha, beta, and gamma,
as well as select the type of RTT (minimum, last, maximum, or average)
used in calculating the actual throughput.
Also we have parameter for using Floyd's slow-start
when gamma is exceeded.
Other differences between our Vegas and the original Vegas paper and the ns implementation
include:
We have experimented using the Vegas gamma threshold during slow-start
to initiate Floyd's slow start (rather than max_ssthresh).
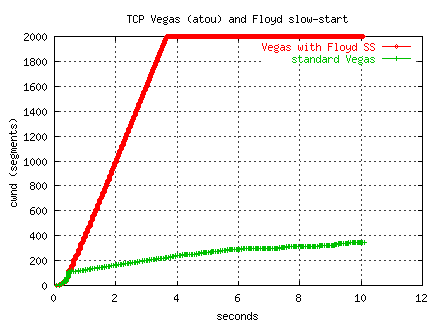
The figure below shows two transfers using a Vegas implementation
over our TCP-over-UDP from PSC to ORNL (OC12, 77ms RTT).
The standard Vegas exits slow-start if the Vegas delta is larger
than gamma and enters congestion avoidance phase.
The standard Vegas (actually using the Floyd AIMD mods) slowly increases
the window in congestion avoidance phase, further dampened by the Vegas
alpha/beta (1/3 in this test) and only reaches 36 Mbs.
The second transfer switches to Floyd's slow-start when gamma is exceeded.
Both transfers exceed gamma at about the 0.5 seconds into the transfer.
The Floyd version climbs quickly to the limiting window of 2000 segments
and reaches an average throughput of 232 Mbs -- nearly a factor of 8
improvement.
Interestingly, for these tests,
the cwnd value when gamma (1) is exceeded is around 120 segments,
close to Floyd's suggested max_ssthresh of 100.
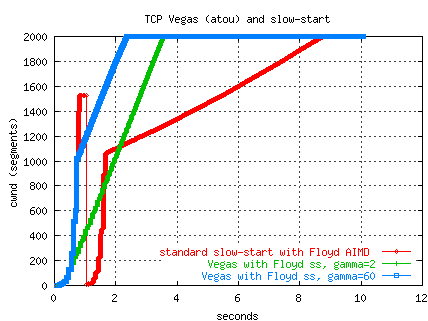
The figure below illustrates three different TCP-over-UDP
transfers from PSC to ORNL.
The path was exhibiting packet drops during slow-start.
The standard slow-start algorithm suffers a loss and recovers using
Floyd's AIMD and reaches an average throughput of 198 Mbs after 10 seconds.
By comparison, the Vegas-controlled transfers exit standard slow-start
when gamma is exceeded and switch to Floyd's modified slow-start
and have no packet losses.
The Vegas flow with a gamma of 2 reaches 219 Mbs,
the flow with a gamma of 60 reaches 229 Mbs.
The following plots show how standard Vegas (alpha=50,beta=80,gamma=400)
is able to avoid queueing and reduce latency when the buffers are
over provisioned at sender and receiver.
The two atou runs were made from a 100 Mb Ethernet host at ORNL
across OC12 to PSC (RTT 77 ms).
The bandwidth delay product suggests a buffer size of 660 segments,
but the transfers use buffers of 1500 segments.
The following plot shows the congestion window for standard TCP versus
standard Vegas (no Floyd slow-start exit), and the value of the Vegas
delta variable during the transfer.
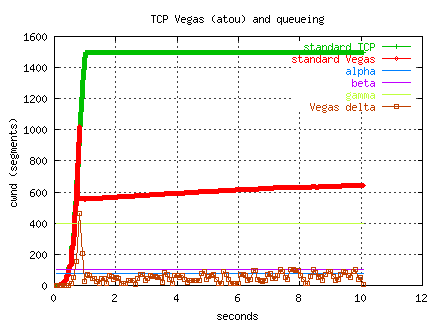
Both flows reach about 85 Mbs at the end of 10 seconds, even though the Vegas
flow backs off in slow-start when delta exceeds gamma (400) and goes
into linear congestion avoidance, slowly incrementing cwnd, metered
by alpha (50) and beta (80).
The standard TCP consumes more buffers and as a consequence the RTT
is increased.
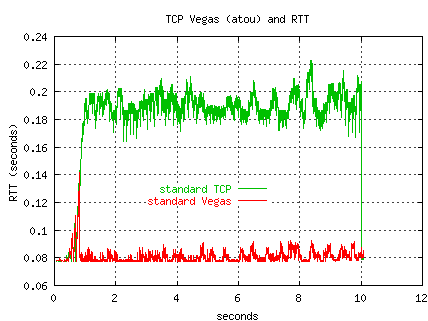
The following plot illustrates how the overprovisioned buffers cause
TCP to suffer increased RTT, while the Vegas RTT stays close to the
minimum RTT for the path.
Here are links to more Vegas info.
Test Cases
1. ORNL-NERSC
We have used the TCP-like UDP client and server in network
configrations other than the two AIX machinies at NERSC and ORNL.
We conducted various experiments between swift and stingray,
using different buffer sizes, different TCP options within AIX,
and different interfaces.
We evaluated both TCP and our TCP-like UDP transport.
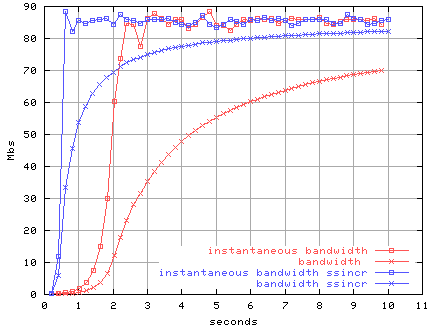
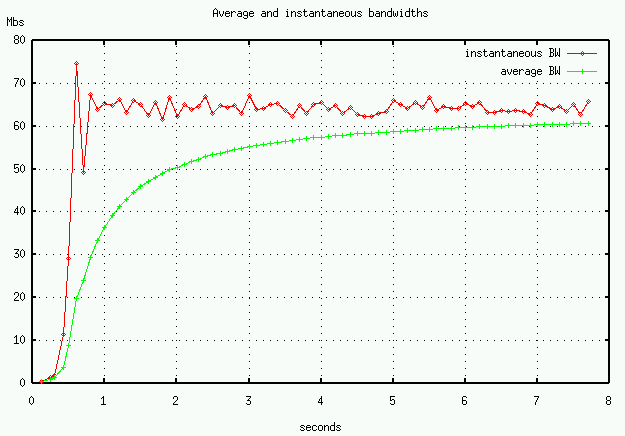
Figure 2 illustrates the throughput behavior
of a TCP flow with no loss.
(Actually, the data was collected from our TCP-like UDP transport.)
TCP (and our TCP-like UDP protocol) starts with a small window
and then exponentially increases it until loss occurs or the
available bandwidth or receiver's window size is reached.
As can be seen in the figure,
in less than a second, available bandwidth is reached.
The rate or time to reach peak can be calculated analytically
as well, since one additional segment (MSS-sized) is transmitted
for each ACK received, which takes one round-trip time.
We can't do anything about the round-trip time, so if we wish
to improve the startup performance we need to have a larger MSS
or try a larger initial window size.
(See the links page for papers on increasing
the initial window size.
Our UDP transport has options for an increasing the MSS and initial window size.)
TCP reaches a steady-state, the transmitter is regulated by
the ACK arrival rate.
Note that it takes many seconds over our ORNL-NERSC path to reach
capacity.
The startup rate can be slowed by a factor of two if the receiver utilizes delayed-ACKs (sending an ACK for every other segment received).
To improve this recovery rate, one either needs a bigger MSS or a larger additive increase in the recovery algorithm. (TCP adds one new segment per RTT.) Using our UDP transport or the simulator, we can experiment with altering this increment. (Increasing the increment turns out to be "fair", because as it is, if multiple TCP flows are sharing a link and there is congestion, they all halve their rates, but the nodes nearer (shorter RTT) will get more of the bandwidth than the distant node. As with startup, a delayed-ACK receiver also slows down the linear recovery. To futher speed recovery, one could reduce cwnd by less than half. We have done a few experiments adjusting these AIMD parameters with our tests harness. Figure 3a compares standard AIMD parameters (0.5,1) with setting cwnd to 0.9 of its value and adding 10 segments per RTT.
See AIMD papers on links page.)
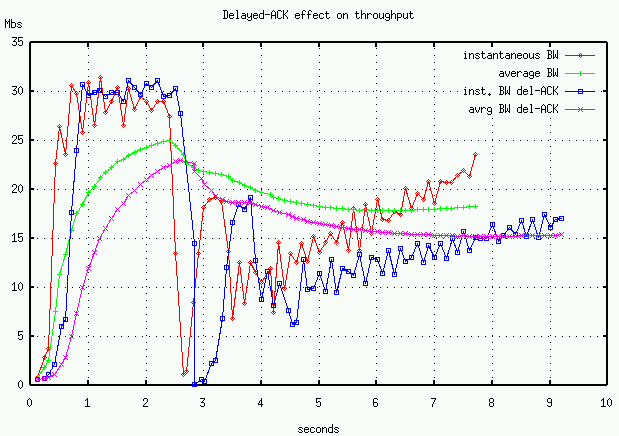
Most TCP-stacks utilize delayed ACKs, our UDP transport can disable delayed-ACKs and profit from a slightly faster startup rate. The effect of delayed-ACK's on throughput is evident in Figure 4. The figure shows average and instantaneous throughput of a TCP-like transfer with and without delayed ACK's. Using the droplist in our TCP-like UDP transport, we have dropped two packets in two transfers from ORNL to NERSC.
Even though the transfers are competing with other Internet traffic, the non-delayed ACK transfer starts up faster and recovers from the loss faster.
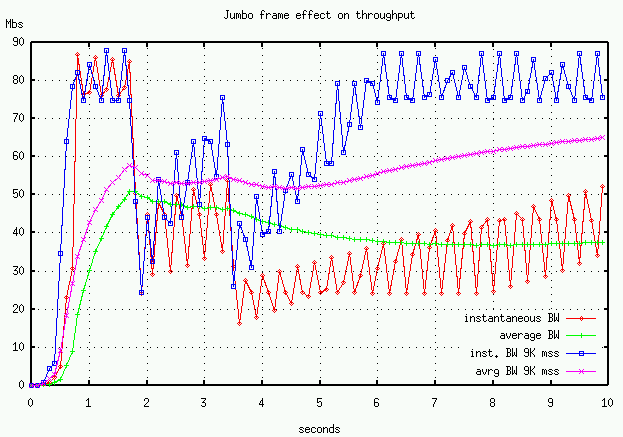
Using this same simulation configuration, Figure 5 compares average and instantaneous throughput for an Ethernet-sized segment (1500B) versus a jumbo-frame segment (9000B). As noted earlier, both startup and recovery times are effected by the segment size. ATM supports a 9K segment size, and FDDI supports a 4K segment, so if both endpoints had different network interfaces and the intervening path supported the larger segment size, then throughput should be improved.
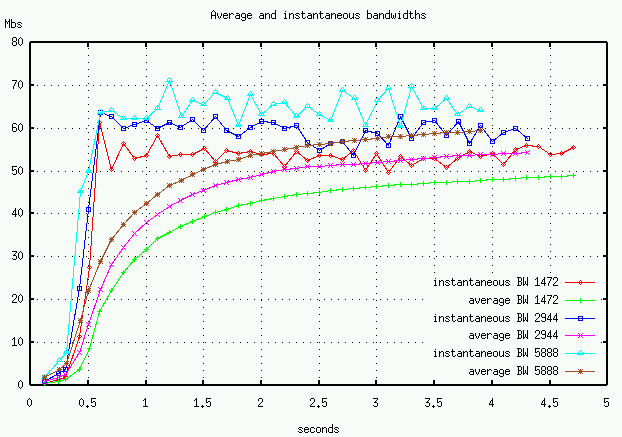
With our TCP-like UDP transport, we can experiment with larger MSS sizes. We used a larger MSS (2944 and 5888 bytes) with our UDP transport and got better throughput. For the same number of bytes transferred and the same effective window size we got 50 Mbs with 1472-byte datagram, 55 Mbs with 2944-byte datagram, and 58 Mbs with 5888-byte datagram. (Figure 6) The UDP datagrams greater than the 1500-byte Ethernet MTU are fragmented by IP. These larger datagrams have an effect similar to TCP's delayed-ACK, in that all fragments (MTU-sized) have to arrive before the receiver ACK's the datagram. Kent and Mogul, however, argue that IP fragmentation usually lowers network performance.
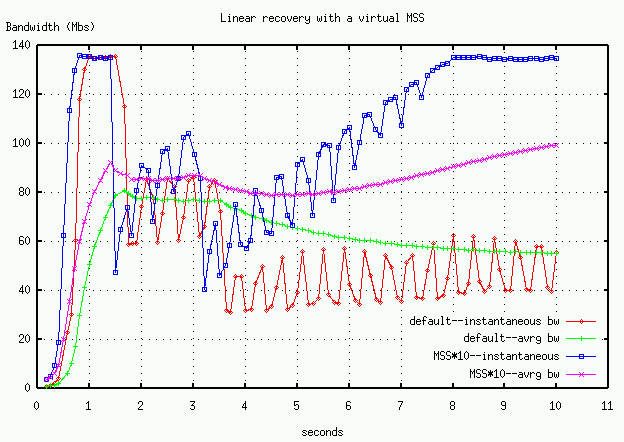
The same effect can be gained by a "virtual MSS", that is choosing an initial startup of K segments (initsegs, and then adding K segments per RTT (increment) during recovery. The virtual MSS avoids the IP fragmentation. (Figure 6a) illustrates a transfer from NERSC to ORNL with two packets drops using the default MSS and then using a virtual MSS of 10 segments. The virtual MSS is also used for slow start, so there is improvement in starting the connection as well.
We have recently ('03) added Kelly's scalable TCP modifications the additive increase. An early comparison of recovery from a single loss can be seen here. This is an atou transfer from ORNL to LBL (80 ms RTT) with window limit of 1500 segments and with no delayed ACKs.
Parallel TCP streams also has the effect of multiplying the MSS by the number of streams, but parallel streams also profits from TCP's fairness by letting the application acquire a greater proportion of the bandwidth from competing application flows. Parallel flows often sustain higher throughput in the presence of loss, because often only one stream is affected, and it can recover to its window-bandwidth faster than a single stream with a larger window.
The configuration values initsegs, ssincr, and thresh_init
affect the rate and duration of slow start.
As noted above, the initial window size (initsegs) can be used
to create a virtual MSS, and there are several papers and RFC drafts
on choosing the initial window size.
Doubling the initial window size reduces the duration of slowstart by
one RTT.
By increasing ssincr from 1 to K, the duration of slowstart is
reduced by factor of log(K)/log(2).
In the figure below, standard slow-start (increment of 1) is compared
to a 10s test using a slow-start increment of 100.
The path is from ORNL to CERN (200 ms RTT)
Though not illustrated below, a larger ssincr will also speed
recovery in those cases where slow-start is used during the initial recovery
phase (e.g., timeouts).
Slow start stops when ssthresh is reached.
In most TCP implementations, the initial value of ssthresh is
infinite, and is set to cwnd/2 when congestion occurs.
If the transfer is not window-limited, our experience has been that
packet loss often occurs during initial slow start, so one can set
thesh_init to some fraction of rcvrwin to try to avoid
this early loss.
Setting thesh_init to zero makes the inital value of ssthresh
infinite.
Floyd's slow-start modifications (max_ssthresh)
and Vegas (gamma) can also moderate slow-start.
2. UT-ORNL
An OC3 (150 Mbs) connects ORNL and UT. We tested throughput with between two 100 Mbs hosts and found that the ATM/OC3 has been provisioned as a VBR link. Using rate-based flooding of UDP packets, we can reach nearly 100Mbs for a short while, then the traffic policing cuts the sustained rate to about 50 Mbs. We saw similar behavior using AAL5. The VBR policy has an interesting affect on TCP, letting it ramp up during slow-start, then dropping segments to bring the sustained rate back down. Choosing a window of about 22KB avoids any packet loss and achieves a bandwidth of 41 Mbs. Larger window sizes induce loss and reduce bandwidth, smaller window sizes cause the transfer to be buffer-limited.
3. ORNL-cable
We tested throuhgput and loss characteristics from a home cable-modem system to ORNL. The route is asymmetric and tortuous, some 20+ hops all the way to the west coast and back. During one test period, the route into the home cable modem appeared to split the traffic across multiple routes. Rate-based UDP flooding could reach 6+ Mbs in to the home without loss, BUT our test software showed that the UDP packets were wildly out of order (60% of the packets). Packets could be displaced by as much as 30 positions. TCP inbound throughput over this path could only reach 700 Kbs, because TCP treats 3 out of order packets as a loss and does a retransmit. With our TCP-like UDP protocol, we increased the "dup threshold" to 9 to account for the massive re-ordering and improved the throughput to 1.7 Mbs.
A more dramatic illustration of the effect of re-ordering is illustrated
in the following bandwidth plot of two flows from LBNL to ORNL (OC12,
80 ms RTT) with a window
of 2000 segments, with delayed ACKs, and with SACK enabled.
(The plot shows bandwidth measured every 0.1 second and the running average.)
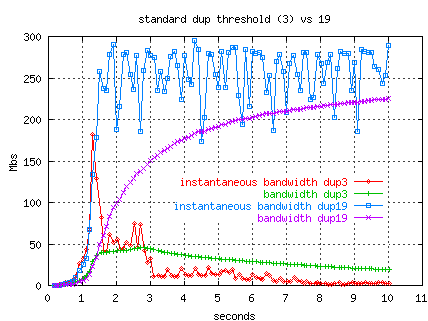
The path out of LBNL exhbits a lot of reordering.
Using the standard threshold of 3, we can achieve only 18 Mbs after
10 seconds because of 9 congestion events resulting in 289 retransmits.
However, the atou server reports 289 duplicate packets received and
a max out-of-order of 7, so none of the packets were actually lost but
were merely out of order.
We ran another test with the client's dup_thresh set to 19.
This flow experiences no losses and reaches 218 Mbs after 10 seconds.
This particular period of heavy reordering lasted several hours
and is probably the result of path through a particular router.
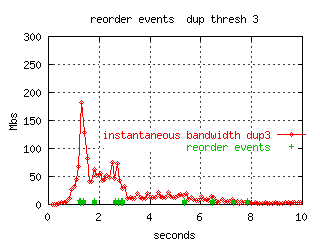
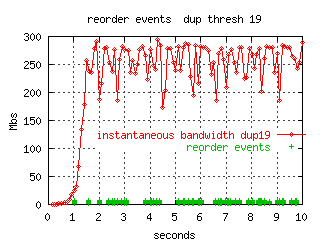
The following figures shows the re-ordering events (green columns)
plotted with the
instantaneous throughput.
In each event, one packet was out of order by 8 slots.
For the threshold 3 example, there were 47 reordering events (0.3% of
packets were out of order).
For the threshold 19 example, there were 309 reordering events (0.2% of
packets were out of order).
The reordering events seem to be related to congestion or data-rate.
The time before the next in order packet arrived was less than a millisecond,
suggesting a reordering anomaly in a particular router.
See our references page for papers
on adjusting TCP to packet reordering.
Linux 2.4 TCP does
a good job of adapating to reordering and "undoing" the associcated
congestion avoidance (see our autotuning page).
4. ORNL-cable (ACK-limited)
The cable modem system we were testing limits data rates from the home to 128 Kbs. This limit in combination with the mutli-hop route actually limited our throughput into the home. Our TCP tests into the home cable modem were actually faster than what we could achieve with our TCP-over-UDP. Our TCP-over-UDP was not using delayed ACKs so there was twice as much bandwidth being consumed on the ACK path, and we were sending empty SACK blocks, further wasting ACK bandwidth. We trimmed off the empty SACK blocks in the ACK path and then enable delayed ACKs in our TCP-over-UDP software and that permitted us to meet or exceed the TCP bandwidth. So for this configuration, delayed ACK's provided a speedup. In some of our ns simulation work we noted that eliminating delayed ACK's also reduced the performance of TCP Vegas. We also have observed that no delayed ACK's during startup (observed with Linux 2.4) may cause packet burst from GigE interfaces that cause drops at some device in the path, so delayed ACKs may be desirable in this case.
We also tested the TCP-over-UDP protocol on slow dialup links, a dual ISDN link, wireless (802.11), Ethernet (10/100), FDDI, GigE, and HiPPI2/GSN links with 64K MTU (reached 1.3 Gbs). We have yet to do rigorous tests comparing the protocol's behavior to TCP, but throughput and loss rates for back-to-back tests are usually quite similar. (This presumes the network hasn't changed "much" ( :-) ) from one test to the next.)
How atou differs from TCP
Our TCP over UDP can do some things that most TCP implementations cannot do.
Our TCP over UDP also cannot do some things that TCP can do.
Summary
Work began on atou in the fall of 2000. We have tested our TCP-like protocol on a variety of networks, and on a number of operating systems, including Linux, Solaris, Sun OS, Irix, FreeBSD, Compaq's OSF, and AIX. We also did a port to Windows as well, though the source files do not contain those modifications. Where TCP could be tuned, we tried to get TCP to match or exceed the UDP client/server data rate. The TCP-like protocol has provided higher throughput in some cases than TCP.
The software provides both a time-stamped packet log and event-based information (entering/leaving recovery, timeouts, out-of-order ACKs, etc.) The debug modes give useful information on which packets were lost, window/threshold changes, bandwidth, round-trip times, and the classical sequence/ACK number graphs. The event and trace data have been very useful in understanding packet loss and throughput on various links.
The TCP-like UDP protocol is appealing because it does not require kernel mods to tweak TCP-like congestion/transport parameters. We have demonstrated striking changes in performance when modifing our transport's buffer size, MSS size, or the AIMD parameters. Disabling delayed ACKs and altering the dup threshold has also improved performance in some networks. For multiple losses within a window, the SACK/FACK options improved recovery as expected. We did not see much effect in altering the burst limit or the initial ssthresh value (limits initial slow start). Since we use slow-start after leaving a congestion event, bursts are reduced.
Future work
Links
See our tech report A TCP-over-UDP Test Harness (June, '02), though the info on this web page is probably more current. Download atou.tar.gz
PSC's Treno uses UDP/ICMP packets and TCP-like slow-start and congestion control to estimate TCP capacity of a path. In November, 2001, Allman describes a UDP-based tool cap with TCP controls that can be used to measure the bulk transfer capacity of a path. Visit the network performance links page for related RFC's and papers.

{kind=link}